Linux高性能服务器编程笔记
阅读《Linux高性能服务器编程》时记录下的笔记
/proc/sys/net/ipv4/下定义了大量tcp连接相关的内核变量。
一些常用的工具:tcpdump、iptables、telnet、nc、netstat、iperf、squid
1 | |
1 | |
1 | |
1 | |
squid是代理服务器,支持正向代理、反向代理
/etc/init.d/目录下有众多服务器程序,如httpd、vsftpd、sshd、mysqld,由脚本程序service(/usr/sbin/service)提供统一管理(start, stop, restart)
1 | |
tcp状态转移:
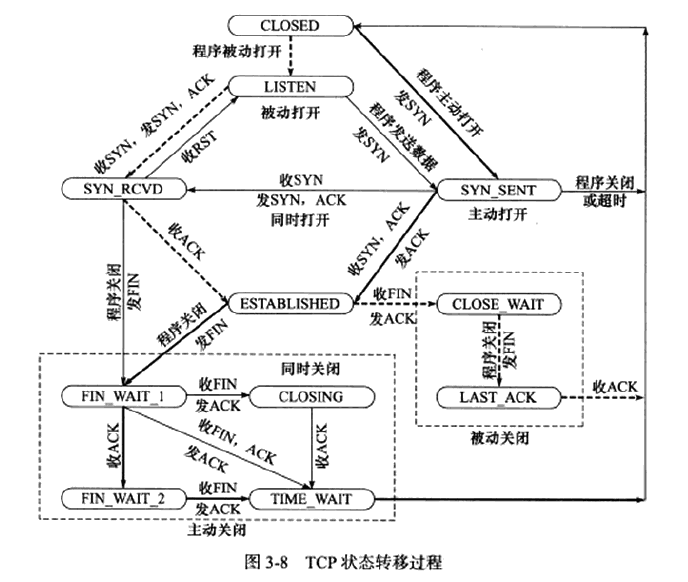
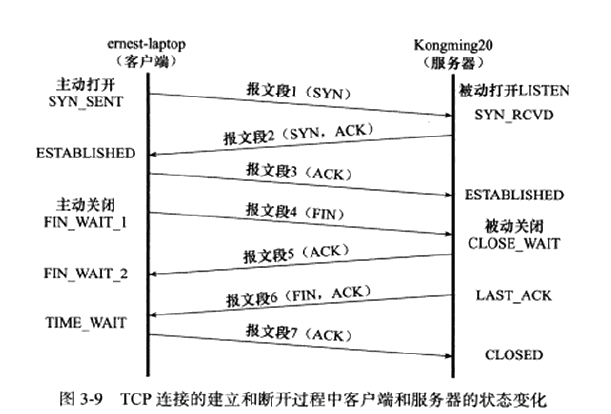
客户端执行半关闭后(FIN_WAIT_2),未等服务器关闭连接就强行退出,此时客户端连接由内核来接管,称为孤儿连接。Linux内核变量定义了最大孤儿连接数(tcp_max_orphans)和最长停留时间(tcp_fin_timeout)
主动断开连接的服务器会由于处于TIME_WAIT状态而不能在原端口(服务器往往运行在知名端口)立即重启,可以通过socket选项SO_REUSEADDR来强制进程立即使用处于TIME_WAIT状态的连接占用的端口。
TCP传输的紧急数据往往又称带外数据(Out Of Band, OOB),紧急指针只会指向紧急数据的下一字节,所以只有带外数据的最后一个字节会作为紧急数据。通常情况下,带外数据存储在特殊的缓存中,带外缓存只有1字节,如果设置SO_OOBINLINE则带外数据将和普通数据一样被存放在TCP接收缓冲区。
Linux中两个TCP超时重传的内核参数tcp_retries1(最少重传次数)、tcp_retries2(最多重传次数)
拥塞控制
接收方通过发送窗口(SWND)控制发送方发送的报文段数量,发送方通过接收通告窗口(RWND)控制发送方的SWND。发送方还有拥塞窗口(CWND),SWND=min(RWND, CWND),这些都以字节为单位。
在使用DNS服务之前,Linux会先进行本地查询,在/etc/hosts配置文件中查找主机名对应的IP地址。
/etc/host.conf文件可以自定义系统解析主机名的方法和顺序
1 | |
Linux网络编程
现代PC大多采用小端字节序,所以小端字节序又称为主机字节序。发送端总是将数据转为大端字节序,所以大端字节序也称为网络字节序。
linux提供一系列主机字节序和网络字节序间转换的函数。
1 | |
Linux将许多东西都看作文件进行处理,socket也是如此。
Socket
socket网络编程中通用biao'ssocket地址的是结构体sockaddr
1 | |

由于14字节的sa_data无法满足多数需求,Linux定义了新的socket地址结构体。
1 | |
为方便使用,Linux提供了协议族的专用socket地址——sockaddr_un(UNIX本地协议族), sockaddr_in(IPv4,#include <netinet/in.h>), sockaddr_in6(IPv6),它们的port应用大端格式(n)
IP地址转换函数
ipv4有以下函数(a表示字符串,n表示二进制数)
1 | |
需要注意的是inet_ntoa返回的是其内部静态变量的指针,所以是不可重入的。
有同时支持IPv4,IPv6的函数(p表示字符串地址,n表示二进制数,af为地址族)
1 | |
inet_pton成功时返回1,失败返回0并设置errno。
inet_ntop成功时返回dst地址,失败则返回NULL并设置errno。cnt用于指定dst的大小,这里往往使用以下宏
1 | |
创建socket
1 | |
命名socket
将socket与socket地址绑定称为给socket命名。通常只有服务器需要命名socket,而客户端采用匿名方式,由操作系统自动分配。
1 | |
监听socket
1 | |
服务端开始监听后,客户端就可以与服务端建立TCP连接。
接收连接
1 | |
发起连接
1 | |
关闭连接
1 | |

数据读写
TCP
1 | |

没有特殊要求就用0
MSG_OOB发送的数据仅有最后一字节会作为OOB数据被接收,且对正常数据的接收会被OOB数据截断,中间夹杂着OOB数据的数据需要多次recv才能读出。
UDP
1 | |
这两个函数同样可以用于面向连接的数据读写,只需要将最后两个参数设置为NULL。
通用数据读写
可以用于TCP、UDP
1 | |
数据存在分散的内存块中,需要分散读(scatter read),发送时一并发送,称为集中写(gather write)
带外标记
由于实际应用中程序不知道什么时候OOB数据到来,Linux提供了函数用于判断下一个被读取的数据是否是带外数据。
1 | |
地址信息函数
1 | |
socket选项
socket文件描述符属性读取和修改
1 | |
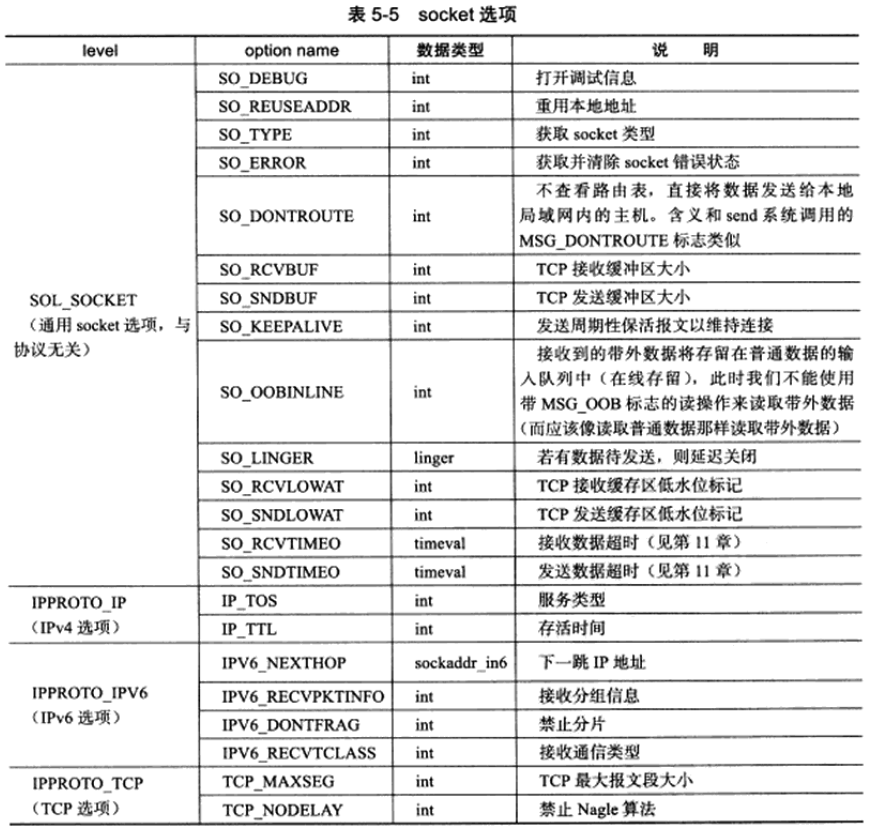
部分选项仅在listen、connect前设置有效:SO_DEBUG、SO_DONTROUTE、SO_KEEPALIVE、SO_LINGER、SO_OOBINLINE、SO_RCVBUF、SO_RCVLOWAT、SO_SNDBUF、SO_SNDLOWAT、TCP_MAXSEG、TCP_NODELAY。
SO_REUSEADDR可以使得sock即使处于TIME_WAIT状态,与之绑定的socket地址也可以立即被重用,也可以通过/proc/sys/net/ipv4/tcp_tw_recycle来快速回收被关闭的socket,从而使得TCP连接根本就不进入TIME_WAIT状态。
SO_RCVBUF、SO_SNDBUF用来控制接收缓冲区和发送缓冲区,setsockopt时实际上是将缓冲区设为max(2*value, min_value)。可以通过/proc/sys/net/ipv4/tcp_rmem和/proc/sys/net/ipv4/tcp_wmem来强制接收缓冲区和发送缓冲区没有最小值限制。
SO_RCVLOWAT和SO_SNDLOWAT是低水位标记,当接收缓冲区的可读数据总数大于其低水位标记时,I/O复用系统调用将通知应用程序可以从对应的socket上读取数据,当发送缓冲区中的空闲空间大于低水位标记时,I/O复用系统调用将通知应用程序可以往对应的socket上写入数据。默认情况下,低水位标记都为1字节。
SO_LINGER用于控制close系统调用的行为。默认情况下,close将立即返回,TCP会把发送缓冲区中残留的数据发送给对方。SO_LINGER选项需要linger结构体。
1 | |
网络信息API
host
1 | |
service
1 | |
需要注意的是以上四个host和service的函数都是不可重入的。可重入版本是函数_r。
1 | |
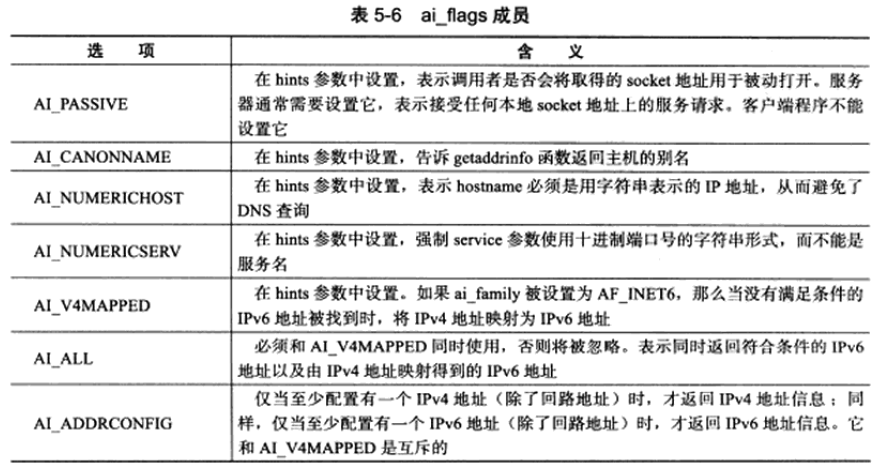
1 | |

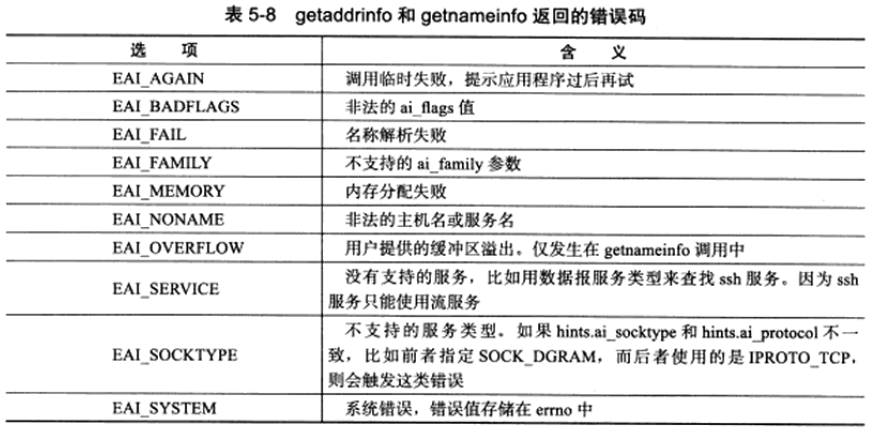
Linux提供了将errno转换成易读字符串形式的函数
1 | |
高级I/O函数
pipe
1 | |
管道容量默认是65536字节,可以通过fcntl函数来修改。
可以通过socketpair方便地创建双向管道
1 | |
dup和dup2
当我们希望将标准输入重定向到一个文件,或者把标准输出重定向到一个网络连接(比如CGI编程)时,可以用该函数。
1 | |
可以通过close原本的文件(比如标准输入、输出),再dup要重定向到的文件,使得新的文件描述符的值恰好与close的相同从而达到重定向的作用。
分散度和集中写
1 | |
sendfile
sendfile用于在两个文件描述符之间直接传递数据(完全在内核中操作,效率很高,零拷贝),通常用于将文件通过网络发送。
1 | |
mmap和munmap
mmap用于申请一段内存空间,可用于进程间通信的共享内存,也可以将文件直接映射到其中
1 | |


其中MAP_SHARED和MAP_PRIVATE互斥。
mmap失败返回MAP_FAILED((void*)-1)并设置errno
splice
用于在两个文件描述符之间移动数据,同样是零拷贝操作
1 | |

tee
用于在两个管道文件描述符之间复制数据,也是零拷贝,且不消耗数据,原文件描述符上的数据仍然可以用于后续的读操作
1 | |
fcntl
对文件描述符进行各种操作
1 | |
常用cmd如下
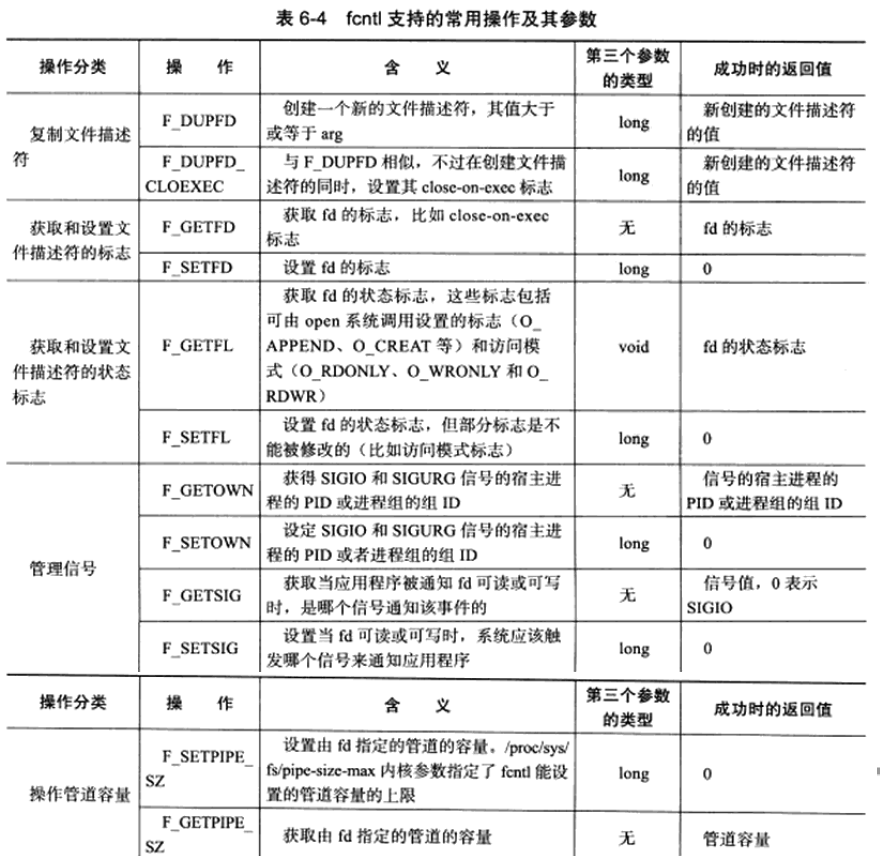
在网络编程中,往往可以用来将文件描述符设置为非阻塞的
1 | |
此外,SIGIO、SIGURG信号必须与某个文件描述符通过fcntl关联后才可使用。
当被关联的文件描述符可读或可写时,系统将触发SIGIO信号,当被关联的文件描述符(必须是一个socket)上有带外数据可读时,系统将触发SIGURG信号。
Linux服务器程序规范
Linux服务器程序一般以后台进程形式运行。后台进程又称守护进程(daemon)。它没有控制终端,因而也不会意外接收到用户输入。守护进程的父进程通常是init进程(PID为1的进程)。
Linux服务器程序通常有一套日志系统,它至少能输出日志到文件,有的高级服务器还能输出日志到专门的UDP服务器。大部分后台进程都在/var/log目录下拥有自己的日志目录。
Linux服务器程序一般以某个专门的非root身份运行。比如 mysqld、httpd、syslogd等后台进程,分别拥有自己的运行账户mysql、 apache和 syslog。
Linux服务器程序通常是可配置的。服务器程序通常能处理很多命令行选项,如果一次运行的选项太多,则可以用配置文件来管理。绝大多数服务器程序都有配置文件,并存放在/etc目录下
Linux服务器进程通常会在启动的时候生成一个PID文件并存入/var/run目录中,以记录该后台进程的PID。比如 syslogd 的PID文件是/var/run/syslogd.pid.
Linux服务器程序通常需要考虑系统资源和限制,以预测自身能承受多大负荷,比如进程可用文件描述符总数和内存总量等。
日志
Linux用一个守护进程(daemon)syslogd来处理系统日志,不过现在的Linux系统上使用的都是它的升级版rsyslogd。
rsyslogd可以接受用户进程和内核的日志。用户进程通过syslog函数生成系统日志,该函数将日志输出到一个AF_UNIX的socket的文件/dev/log中,rsyslogd则监听该文件以获取用户进程的输出。内核日志在老的Linux系统上是通过另一个守护进程rklogd来管理的,rsyslogd则是利用额外的模块实现了相同的功能。内核日志由printk等函数打印至内核的ring buffer中,ring buffer的内容则直接映射到/proc/kmsg文件中。rsyslogd通过读取该文件获得内核日志。
rsyslogd会对收到的日志进行分发。默认情况下,调试信息会保存至/var/log/debug,普通信息保存至/var/log/messages,内核消息保存至/var/log/kern.log。可以在/etc/rsyslog.conf文件进行配置(主配置文件,子配置文件通常为/etc/rsyslog.d/*.conf)。
1 | |
为了修改日志的格式,可以使用openlog函数
1 | |
为过滤日志
1 | |
1 | |
用户
进程拥有两个用户ID: UID、EUID。用户运行某程序的代码时拥有该程序的EUID权限。同样组也有类似的EGID。EUID为root的进程称为特权进程。
1 | |
进程间关系
Linux下每个进程都隶属于一个进程组,因此它们除了PID外还有PGID。
1 | |
每个进程组都有一个首领进程,其PGID和PID相同。进程组将一直存在,直到其中所有进程都退出,或者加入到其他进程组。
1 | |
一个进程只能设置自己或者其子进程的PGID,并且当子进程调用exec系列函数后不能再在父进程中对它设置PGID。
非首领进程可以创建会话。
1 | |
系统资源限制
1 | |
普通程序可以减小硬限制,只有root身份运行的程序才能增加硬限制。
可以使用ulimit命令修改当前shell环境下的资源限制,这种修改对该shell启动的所有后续程序有效。也可以通过修改配置文件来修改,这种修改永久生效。

改变工作目录和根目录
1 | |
服务器程序后台化
1 | |
实际上,Linux提供了完成同样功能的库函数
1 | |
高性能服务器程序框架
I/O模型
socket创建时默认阻塞,可以通过socket系统调用的第二个参数传递SOCK_NONBLOCK或通过fcntl的F_SETFL设置非阻塞。
socket的基本API中,可能被阻塞的系统调用包括accept、send、recv、connect。
针对非阻塞的I/O执行的系统调用总是立即返回,如果事件没有立即发生,则这些系统调用返回-1.对于非阻塞的accept、send、recv,事件未发生时errno通常被设置成EAGAIN或EWOULDBLOCK,对于connect则是EINPROGRESS。
非阻塞I/O通常要与其他I/O通知机制一起使用,比如I/O复用和SIGIO信号。
I/O复用是最常用的I/O通知机制,应用程序通过I/O服用函数向内核注册一组事件,内核通过I/O复用函数把其中就绪的事件通知给应用程序,如select、poll、epoll_wait。I/O复用函数本身是阻塞的,它们能提高程序效率的原因在于它们能同时监听多个I/O事件。
SIGIO信号也可以用来报告I/O事件。可以为一个文件描述符指定宿主进程,当该文件描述符上有事件发生时,宿主进程将捕获到SIGIO信号,SIGIO信号的信号处理函数将被触发。
异步I/O的读写操作总是立即返回,而不论I/O是否阻塞,I/O读写由内核接管,内核通知I/O完成事件。

两种高效的事件处理模式
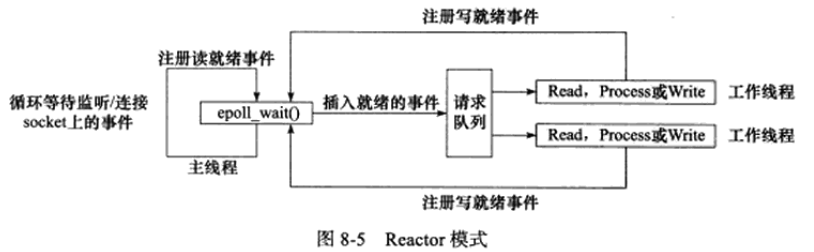
Reactor
主线程(I/O处理单元)只负责监听文件描述上是否有事件发生,有的话立即将该事件通知工作线程(逻辑单元)。除此之外,主线程不做任何其他实质性的工作。读写数据,接收新的连接,以及处理客户请求均在工作线程中完成。
使用同步I/O模型(以epoll_wait为例)实现的Reactor模式的工作流程是:
- 主线程往epoll内核事件表中注册socket上的读就绪事件
- 主线程调用epoll_wait等待socket上有数据可读
- 当socket上有数据可读时,epoll_wait通知主线程。主线程则将socket可读事件放入请求队列
- 睡眠在请求队列上的某个工作线程被唤醒,它从socket读取数据,并处理客户请求,然后往epoll内核事件表中注册该socket上的写就绪事件
- 主线程调用epoll_wait等待socket可写
- 当socket可写时,epoll_wait通知主线程。主线程将socket可写事件放入请求队列
- 睡眠在请求队列上的某个工作线程被唤醒,它往socket上写入服务器处理客户请求的结果
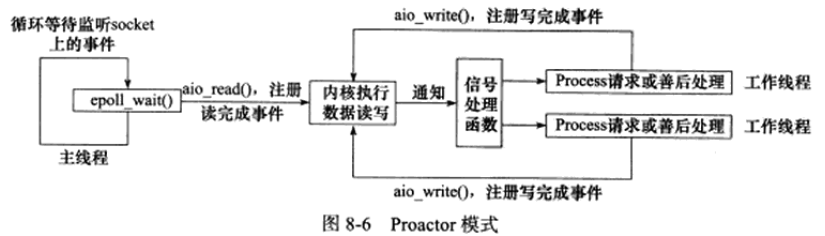
Proactor
所有I/O操作都交给主线程和内核来处理,工作线程仅仅负责业务逻辑。
使用异步I/O模型(以aio_read和aio_write为例)实现的Proactor模式的工作流程是:
- 主线程调用aio_read函数向内核注册socket上的读完成事件,并告诉内核用户读缓冲区的位置,以及读操作完成时如何通知应用程序(这里以信号为例,详情请参考sigevent的man手册)
- 主线程继续处理其他逻辑
- 当socket上的数据被读入用户缓冲区后,内核将向应用程序发送一个信号,以通知应用程序数据已经可用
- 应用程序预先定义好的信号处理函数选择一个工作线程来处理客户请求。工作线程处理完客户请求之后,调用aio_write函数向内核注册socket上的写完成事件,并告诉内核用户写缓冲区的位置,以及写操作完成时如何通知应用程序(仍然以信号为例)
- 主线程继续处理其他逻辑
- 当用户缓冲区的数据被写入socket之后,内核将向应用程序发送一个信号,以通知应用程序数据已经发送完毕
- 应用程序预先定义好的信号处理函数选择一个工作线程来做善后处理,比如决定是否关闭socket。
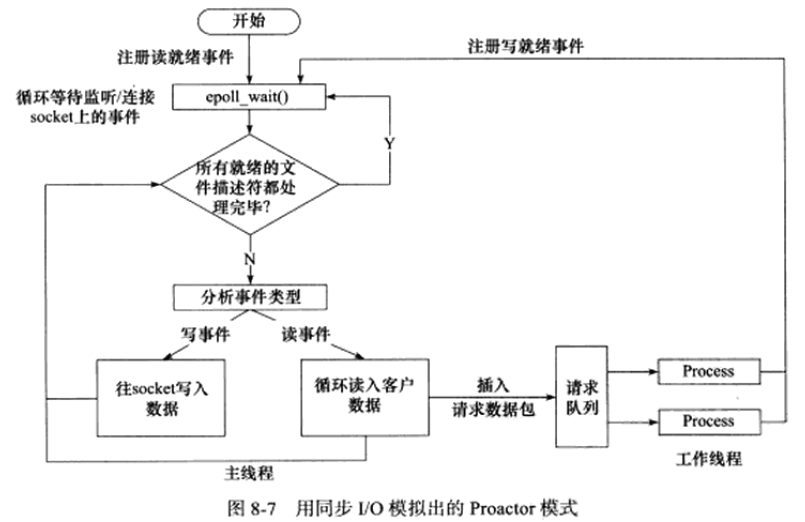
用同步I/O模拟Proactor
以epoll_wait为例
- 主线程往epoll内核事件表中注册socket上的读就绪事件
- 主线程调用epoll_wait等待socket上有数据可读
- 当socket上有数据可读时,epoll_wait通知主线程。主线程从socket循环读取数据,直到没有更多数据可读,然后将读取到的数据封装成一个请求对象并插入请求队列
- 睡眠在请求队列上的某个工作线程被唤醒,它获得请求对象并处理客户请求,然后往epoll内核时事件中注册socket上的写就绪事件
- 主线程调用epoll_wait等待socket可写
- 当socket可写时,epoll_wait通知主线程,主线程往socket上写入服务器处理客户请求的结果
两种高效的并发模式
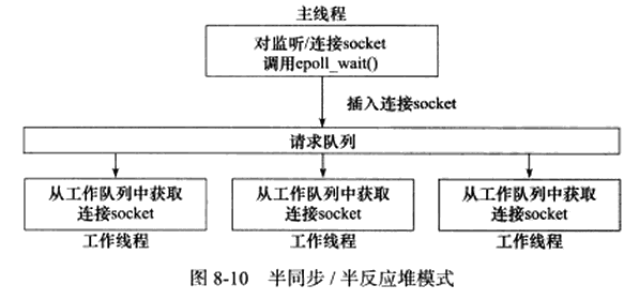
半同步/半异步(half-sync/half-async)模式
同步线程用于处理客户逻辑,异步线程用于处理I/O事件。
一种变体成为半同步/半反应堆(half-sync/half-reactive)模式
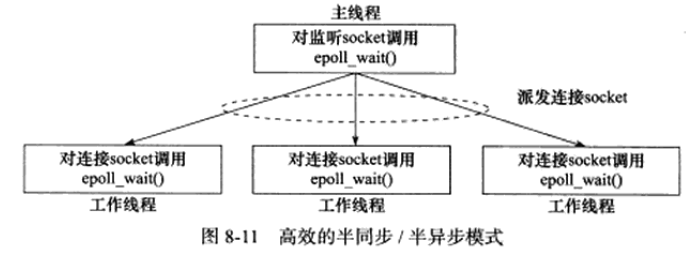
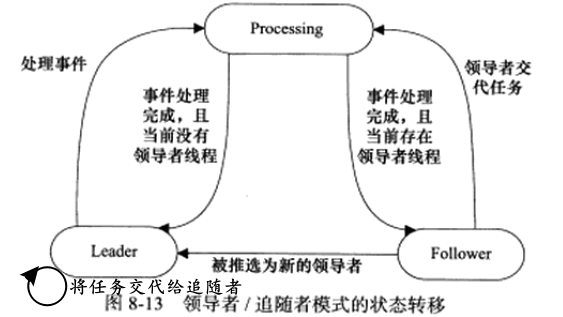
领导者/追随者(Leader/Followers)模式
多个工作线程轮流获得事件源集合,轮流监听、分发并处理事件的一种模式
在任意时间点,程序都仅有一个领导者线程,它负责监听I/O事件,而其他线程都是追随者,他们休眠在线程池中等待成为新的领导者。当前的领导者如果检测到I/O事件,首先要从线程池中推选出新的领导者线程,然后处理I/O事件。此时,新的领导者等待新的I/O事件,而原来的领导者则处理I/O事件。
包含组件:HandleSet、ThreadSet、EventHandler、ConcreteEvetHandler
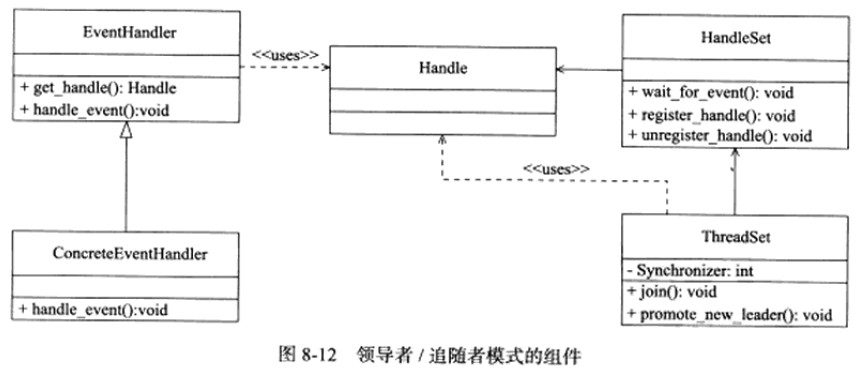
HandleSet
- Handle用于表示I/O资源
- wait_for_event监听句柄上的I/O事件,将就绪事件通知给领导者线程
- 领导者线程调用绑定到Handle上的事件处理器处理事件(绑定由register_handle实现)
ThreadSet
- 线程集中的线程必定处于三种状态之一
- Leader: 当前处于领导者身份,负责等待句柄集上的I/O事件
- Processing: 正在处理事件。领导者检测到I/O事件后可以转移到Processing状态进行处理,并调用promote_new_leader推选新的领导,也可以指定其他追随者来处理事件(Event Handoff),此时领导者的身份不变。当处于Processing状态的线程处理完事件之后,如果当前线程集中没有领导者,则它成为新的领导者,否则它就直接转变为追随者
- Follower: 当前处于追随者身份,通过调用线程集的join方法等待成为新的领导者,也可能被当前的领导者指定来处理新的任务
ConcreteEventHandler
- 是事件处理器的派生类,必须重新实现基类的handle_event方法
有限状态机
池
内存池、进程池、线程池和连接池
I/O复用
select
在一段指定时间内,监听用户感兴趣的文件描述符上的可读、可写和异常等事件。
1 | |
1 | |
1 | |
网络编程中,socket可读就绪:
- socket内核接收缓存区中的字节数大于等于其低水位标记SO_RCVLOWAT
- socket通信对方关闭连接
- 监听socket上有新的连接请求
- socket上有未处理的错误(此时可以使用getsockopt来读取和清除该错误)
socket可写就绪:
- socket内核发送缓冲区中的可用字节数大于等于其低水位标记SO_SNDLOWAT
- socket的写操作被关闭。对写操作被关闭的socket执行写操作将触发一个SIGPIPE信号
- socket使用非阻塞connect连接成功或失败(超时)之后
- socket上有未处理的错误(此时可以使用getsockopt来读取和清除该错误)
异常就绪:
- socket上接收到带外数据
poll
与select类似,也是在指定时间内轮询一定数量的文件描述符,以测试其中是否有就绪者。
1 | |
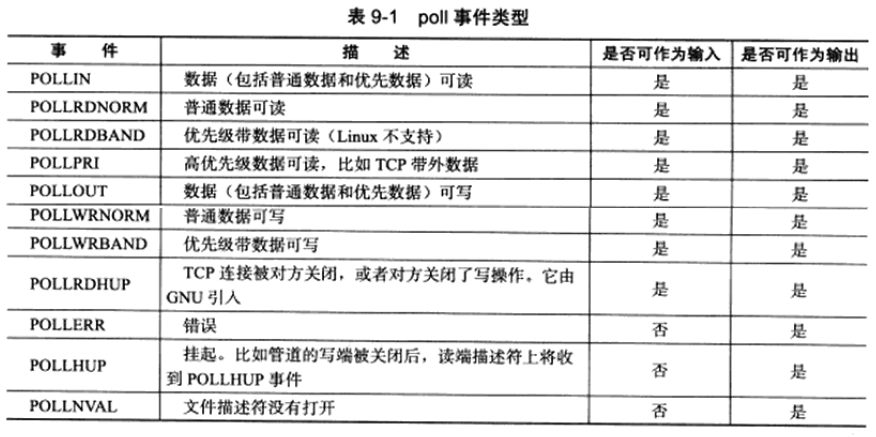
POLLRDNORM、POLLRDBAND、POLLWRNORM、POLLWRBAND由XOPEN规范定义,它们实际上是将POLLIN事件和POLLOUT事件分得更细致,以区别对待普通数据和优先数据,但Linux并不完全支持它们。
使用POLLRDHUP事件时需要在代码最开始处定义_GNU_SOURCE。
epoll系列系统调用
epoll是Linux特有的I/O复用函数,使用一组函数完成任务。
epoll把用户关心的文件描述符上的事件放在内核里的一个事件表中,从而无须像select和poll那样每次调用都要重复传入文件描述符集或事件集。
epoll需要使用一个额外的文件描述符来标识内核中的事件表。
1 | |
通过epoll_ctl对事件表进行修改。
1 | |
1 | |
epoll对文件描述符有两种操作模式:LT(电平触发)模式和ET(边沿触发)模式。LT是默认的工作模式,这种模式下epoll相当于一个效率较高的poll。当往epoll内核事件表中注册一个文件描述符上的EPOLLET事件时,epoll将以ET模式来操作该文件描述符。ET模式是epoll的高效工作模式。
对于采用LT工作模式的文件描述符,当epoll_wait检测到其上有事件发生并将此事件通知应用程序后,应用程序可以不立即处理此事件。当应用程序下一次调用epoll_wait时,epoll_wait还会再次向应用程序通报该事件,直到事件被处理。
对于采用ET模式的,通知后,应用程序必须立即处理该事件,后续的epoll_wait调用将不再向应用程序通知该事件。
从实现上来看,ET和LT的区别在于事件就绪的判断。
对于LT
- 读操作:缓冲区不为空
- 写操作:缓冲区不为满
对于ET
- 读操作
- 缓冲区内容变多
- 缓冲区不为空且EPOLLIN事件 EPOLL_CTL_MOD
- 读操作
- 缓冲区内容减少
- 缓冲区不为满且EPOLLOUT事件 EPOLL_CTL_MOD
即使使用ET模式,一个socket上的某个事件还是可能被触发多次。一个线程在读取完某个socket上的数据后开始处理这些数据,而数据处理过程中该socket上又有新的数据可读(EPOLLIN再次触发),此时另一个线程又被唤醒来读取这些数据。于是就出现了两个线程同时操作一个socket的局面。为避免该问题,可以使用EPOLLONESHOT。
对于注册了EPOLLONESHOT事件的文件描述符,操作系统最多触发其上注册的一个可读、可写或异常事件,且只触发一次,直到再次使用epoll_ctl函数重置该文件描述符上注册的EPOLLONESHOT事件(EPOLL_CTL_MOD)。
三种I/O复用函数比较
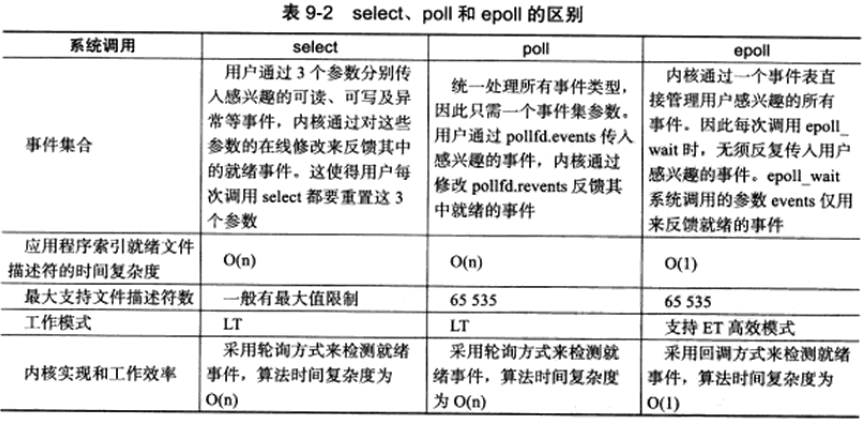
epoll直接将事件结果复制到数组中,避免了遍历,因而更适用连接数量多而活动连接较少的情况。
select一般有最大值限制,虽然可以修改,但容易产生不可预期的错误。
I/O复用的高级应用
非阻塞的socket进行connect,如果返回时连接还没有建立,将设置errno为EINPROGRESS。在这种情况下,我们应监听这个连接暂时失败的socket上的可写事件。当select、poll等函数返回后,利用getsockopt来读取错误码并清除该socket上的错误。如果错误码是0则连接成功建立,否则失败。但需要注意的是,这方法存在移植性问题。首先,非阻塞的socket可能导致connect始终失败。其次,select对处于EINPROGRESS状态下的socket可能不起作用。最后,对于出错的socket,getsockopt在不同系统上返回值不一样,Linux返回-1,伯克利的UNIX返回0。
同一个端口可以创建多个socket用于处理不同服务如TCP、UDP。
超级服务xinetd
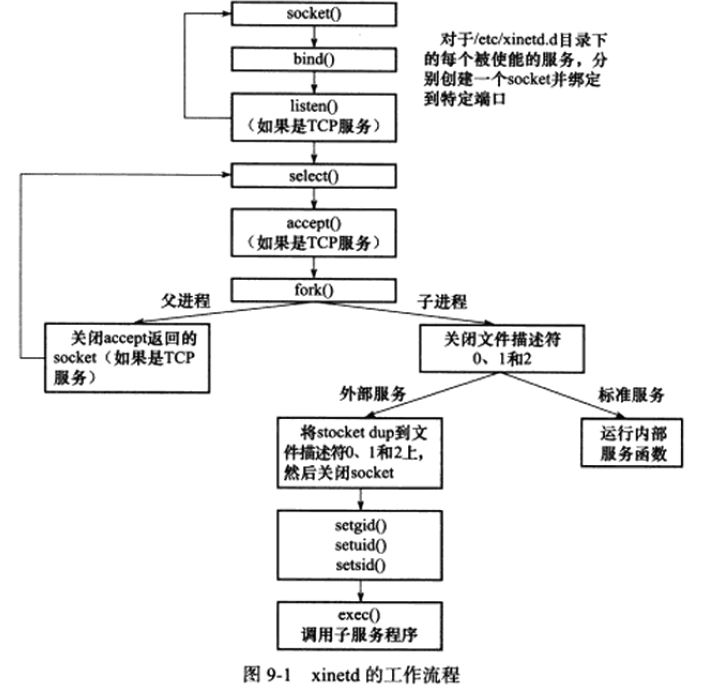
Linux因特网服务inetd是超级服务,同时管理着多个子服务,即监听多个端口。现在Linux系统上使用的inetd服务程序通常是其升级版xinetd。它新增了一些控制选项,提高了安全性。
主配置文件/etc/xinetd.conf,/etc/xinetd.d子配置文件夹
它的子服务telnet的配置文件/etc/xinetd.d/telnet典型内容如下
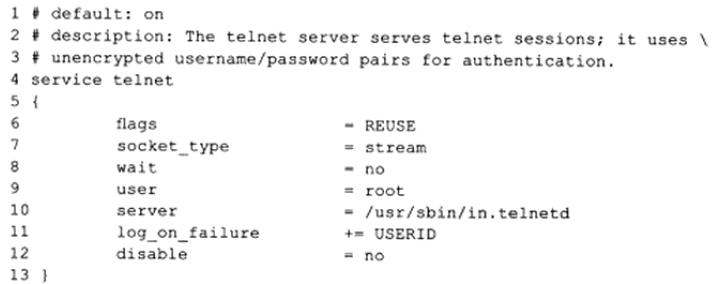
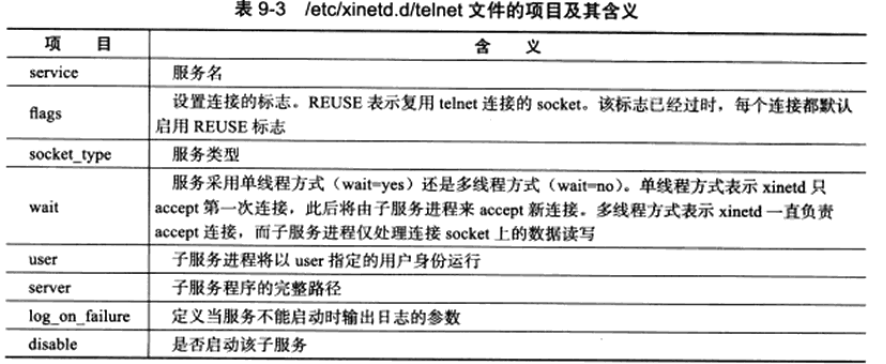
对于其他更多配置,可以参考man。
信号
信号的产生
- 对于前台进程,用户可以通过输入特殊的终端字符来给它发送信号。比如Ctrl+c通常会给进程发送一个中断信号
- 系统异常。比如浮点异常和非法内存访问
- 系统状态变化。比如alarm定时器到期将引起SIGALRM信号
- 运行Kill命令或调用kill函数
服务器程序必须处理(或至少忽略)一些常见的信号,以免异常终止。
linux使用kill函数发送信号
1 | |


用户可以通过给信号绑定信号处理函数来实现对信号的响应。信号处理函数应该是可重入的,并且由于我们希望同一个信号在多次触发时能够不被屏蔽,信号处理函数应该能够迅速执行完,所以信号处理函数往往只是作为一个中介,将信号值通过管道传递给主循环。
1 | |
除了自定义信号处理函数,Linux还提供了两个特殊的标识来进行其他处理
1 | |
Linux将可用信号(标准信号+POSIX实时信号)都定义在bits/signum.h中
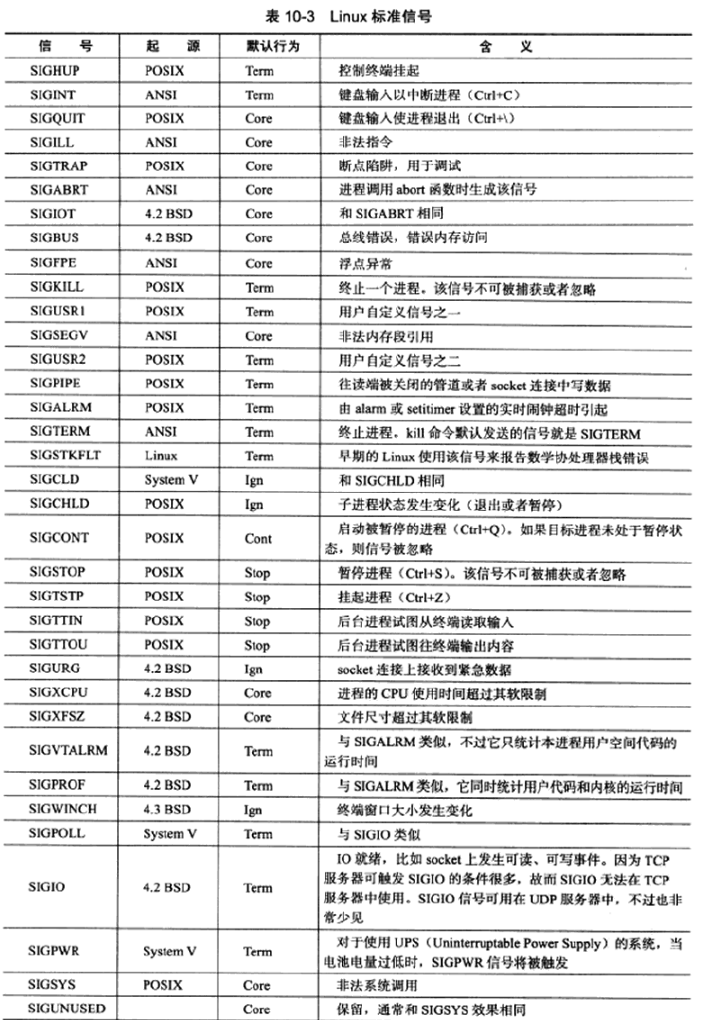
如果程序在执行处于阻塞状态的系统调用时收到信号,并且该信号设置了信号处理函数,则默认情况下系统调用将被中断并且errno被设置为EINTR。可以使用sigaction函数为信号设置SA_RESTART标志以自动重启被该信号中断的系统调用。
对默认行为是暂停进程的信号(比如SIGSTOP、SIGTTIN),如果没有设置信号处理函数,它们也是可以中断某些系统调用的(比如connect、epoll_wait)。这是Linux独有的。
绑定信号处理函数使用signal系统调用
1 | |
但这个系统调用基本deprecated了,更常用的是sigaction。
1 | |
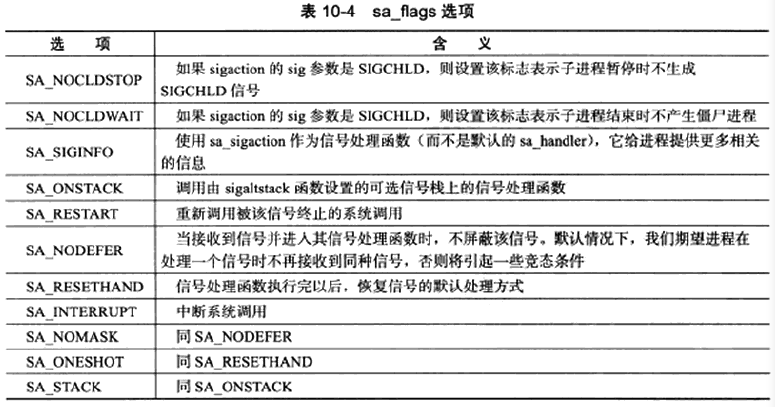
1 | |
如果只是想要设置/获得进程掩码,可以使用
1 | |
设置信号掩码后,被屏蔽的信号将不能被进程接收,但该信号会被暂时挂起。此时如果取消屏蔽,它依然能被进程接收到。
1 | |
显然,即使该信号被多次触发,也只能被检测到一次。
网络编程相关信号
SIGHUP
当挂起进程的控制终端时,SIGHUP信号将被触发。对于没有控制终端的网络后台程序而言,这个信号往往是强制要求服务器重读配置文件。
SIGPIPE
默认情况下,往一个读端关闭的管道或者socket连接中写数据将引发SIGPIPE,程序接收到SIGPIPE信号的默认行为是结束进程,所以往往需要在代码中捕获并处理该信号,或者至少忽略它。引起SIGPIPE信号的写操作将设置errno为EPIPE。
我们可以使用send函数的MSG_NOSIGNAL标志来禁止写操作触发SIGPIPE信号。在这种情况下应使用send函数反馈的errno来判断管道或socket连接的读端是否已经关闭。也可以用I/O复用系统调用来检测。管道的读端关闭时,写端文件描述符上的POLLHUP事件将被触发,socket连接被对方关闭时,socket上的POLLRDHUP事件将被触发。
SIGURG
收到带外数据
定时器
Linux提供了三种定时方法
- socket选项SO_RCVTIMEO和SO_SNDTIMEO
- SIGALRM信号
- I/O复用系统调用的超时参数
socket选项SO_RCVTIMEO和SO_SNDTIMEO

SIGALRM信号
由alarm和setitimer函数设置的实时闹钟一旦超时,将触发SIGALRM信号。
如果不需要非常精确,可以使用alarm
1 | |
getitimer/setitimer通过which参数提供了更精确的时间选项。
1 | |
| which | description |
|---|---|
| ITIMER_REAL | 以系统真实的时间来计算,它送出SIGALRM信号 |
| ITIMER_VIRTUAL | 以该进程在用户态下花费的时间来计算,它送出SIGVTALRM信号 |
| ITIMER_PROF | 以该进程在用户态下和内核态下花费的时间来计算,它送出SIGPROF信号 |
I/O复用系统调用的超时参数
如果epoll_wait的返回值等于0,则过去了timeout时间,否则经过了(end - start) * 1000ms。
高性能定时器
时间轮(TimingWheel)
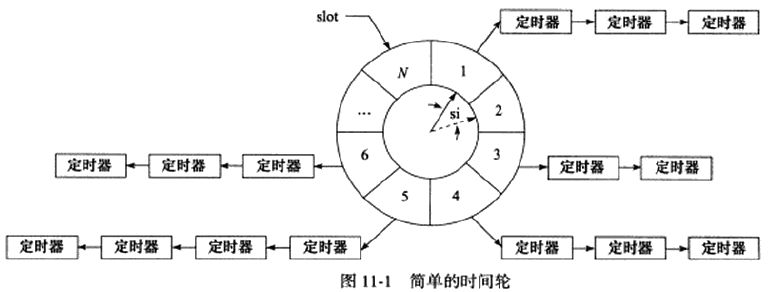
指针指向当前所在的时间槽slot,每个tick(slot interval, si)移动到下一个槽。每个槽都是一个定时器链表。指针每指向一个槽,都要遍历该槽里的所有定时器。指针花费N*si走完一个round,不是所有定时器都在一个round内的,所以每个定时器还有个round变量记录还剩几个round才到时间,如果指针指向定时器所在的槽且定时器的round为0则表明时间到。
若当前指针指向槽cs,要添加一个定时时间为ti的定时器,则该定时器应被插入槽ts的链表中,有 ts = ( cs + ( ti / si ) ) % N 如果想要提高定时精度,需要si够小;要提高执行效率,需要N购大。
可以实现多层级的时间轮控制不同粒度的定时。
时间堆
每次都以所有定时器中超时值最小的定时器的超时值发出SIGALRM,一旦SIGALRM,则最小的定时器必然到期。我们可以处理该定时器然后找出下一个超时时间最小的定时器并设置。最小堆非常适合于解决该问题。
高性能I/O框架库Libevent
ACE、ASIO、Libevent都是开源的优秀的I/O框架库,其中Libevent相对轻量级。
基于Reactor模式实现的I/O框架库包含组件:句柄、事件多路分发器(EventDemultiplexer)、事件处理器(EventHandler)和具体的事件处理器(ConcreteEventHandler)。
事件源:I/O事件、信号和定时事件
一个事件源通常和一个句柄绑定在一起。当内核检测到事件发生时,它将通过句柄来通知应用程序这一事件。Linux的I/O事件的句柄是文件描述符,信号事件的句柄是信号值。
I/O框架库一般将系统支持的各种I/O复用系统调用封装成统一的接口,称为事件多路分发器。它的demultiplex方法是等待事件的核心函数。
当事件多路分发器检测到有事件发生时,通过句柄通知应用程序。事件处理器需与句柄绑定。
事件处理器一般提供一个get_handle方法,它返回与该事件处理器关联的句柄。
Reactor提供几个主要方法
- handler_events: 执行事件循环。重复如下过程:等待事件,然后依次处理所有就绪事件对应的事件处理器
- register_handler: 调用事件多路分发器的register_event方法来往事件多路分发器中注册一个事件
- remove_handler: 调用事件多路分发器的remove_event方法来删除事件多路分发器中的一个事件。
Libevent跨平台支持、统一事件源、线程安全,基于Reactor模式实现。
1 | |
事件由事件多路分发器管理,事件处理器则由事件队列管理。
总体流程
- 调用event_init创建event_base对象,相当于Reactor实例
- 用event_new(evsignal_new、evtimer_new)创建事件处理器
- 用event_add将事件处理器添加到注册事件队列中,并将该事件处理器对应的事件添加到事件多路分发器中,相当于register_handler
- 调用event_base_dispatch执行事件循环
- 使用*_free来释放系统资源
struct event有许多指针,这些指针将多个struct
event串成了多个尾队列。ev_next形成注册事件队列;ev_active_next形成活动事件队列(活动事件队列不止一个,不同优先级的事件处理器被激活后插入不同的活动事件队列。在事件循环中,Reactor将按优先级从高到低遍历所有活动事件队列);联合体ev_timeout_pos在通用定时器(即简单链表实现的)中用ev_next_with_common_timeout形成通用定时器队列,在时间堆中用min_heap_idx指示位置。一个定时器是否要采用通用定时器取决于其超时值大小;联合体_ev用ev_ioev_io_next形成具有相同文件描述符的I/O事件队列,用ev_signal.ev_signal_next形成信号事件队列,ev_signal.ev_ncalls指定信号事件发生时Reactor需要执行多少次该事件对应的事件处理器的回调函数(在启用ev_flags的EV情况下),ev_pncalls要么NULL,要么指向它。
ev_res记录当前激活事件的类型。
ev_flags如下
1 | |
ev_pri为优先级,越小优先级越高
ev_closure定义执行回调函数时的行为
1 | |
ev_timeout仅对定时器有效
多进程编程
fork
1 | |
exec系列系统调用
替换当前进程映像
1 | |
处理僵尸进程
父进程一般需要跟踪子进程的退出状态。当子进程结束运行后,内核不会立即释放该进程的进程表表项。在子进程结束运行之后,父进程读取其状态之前,称该子进程处于僵尸态。父进程先于子进程结束,子进程的PPID被设置为1,即init进程,init进程接管了该子进程,并等待其结束,该状态子进程也称为僵尸态。停留在僵尸态的子进程依然占据着内核资源。
1 | |

在事件已经发生的情况下执行非阻塞调用才能提高程序的效率。子进程在结束时会给父进程发送SIGCHLD信号,父进程可以通过该信号得知子进程是否结束,并在知道结束后调用waitpid以彻底结束它。
进程间通信
用管道在父子间通信
fork后原先打开的管道文件描述符fd[0]和fd[1]依然处于打开状态,由于一对管道只能保证一个方向的数据传输,所以父进程和子进程必须有一个关闭fd[0],另一个关闭fd[1]。
无关联进程之间的通信
FIFO管道
有一种特殊的管道称为FIFO(先进先出),也叫命名管道。它能用于无关联进程之间的通信,但网络编程中使用不多。
信号量(Semaphore)
Linux/Unix常用P(传递)、V(释放)来代替信号量中的wait、signal。
对于信号量SV
- P(SV): 如果SV的值大于0,则减1,继续执行;如果为0,则挂起进程的执行
- V(SV): 如果有其他进程因为等待SV而挂起,就唤醒一个被挂起的进程;如果没有,则将SV加一
semget系统调用
1 | |
semget函数在创建信号量集时会对与之关联的内核数据结构体semid_ds执行创建并初始化操作
1 | |
semop系统调用
与每个信号量关联的一些重要的内核变量
1 | |
semop对信号量的操作实际上就是对这些内核变量的操作
1 | |
semctl系统调用
1 | |
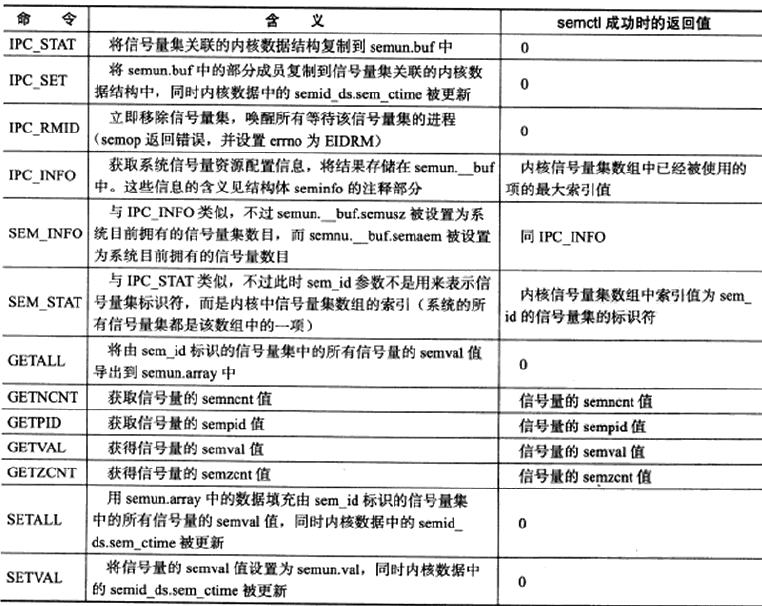
除GETNCNT、GETPID、GETVAL、GETZCNT、SETVAL的其他操作都是针对整个信号量集的,此时semctl的参数sem_num被忽略
共享内存
共享内存是效率最高的IPC,但是往往需要配合一些其他手段来防止竞态。
1 | |
1 | |
1 | |
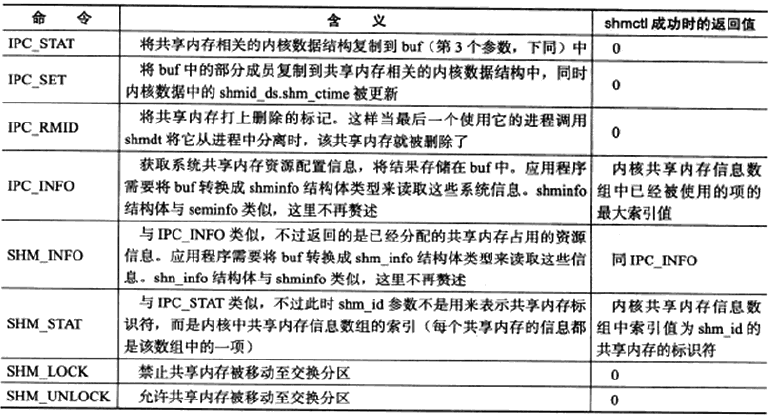
共享内存的POSIX方法
利用mmap和它的MAP_ANONYMOUS可以实现父子进程之间的匿名内存共享。
通过打开同一个文件,mmap也可以实现无关进程之间的内存共享。
1 | |
消息队列
消息队列是在两个进程之间传递二进制块数据的一种简单有效的方式,每个数据块都有一个特定的类型,接收方可以根据类型来有选择地接收数据,而不一定像管道和命名管道那样必须以先进先出的方式接收数据。
1 | |
1 | |
1 | |
1 | |

IPC命令
ipcs命令可以查看当前系统上有哪些共享资源实例
可以使用ipcrm命令删除遗留在系统中的共享资源
进程间传递文件描述符
只要传递文件描述符的值就好了
多线程编程
线程
NPTL是目前Linux的标准线程库,内核线程与用户线程1:1。
1 | |
一个用户可以打开的线程数量不能超过RLIMIT_NPROC软资源限制。系统上所有用户能创建的线程总数也不能超过/proc/sys/kernel/threads-max内核参数所定义的值。
线程函数在结束时最好调用如下函数以确保安全、干净地退出
1 | |
pthread_exit通过retval参数项线程的回收者传递其退出信息,它永远不会失败。
一个进程中的所有线程都可以调用pthread_join函数来回收其他线程(前提是目标线程是可回收的)。
1 | |

希望异常终止一个线程(取消线程)时
1 | |
接收到取消请求的目标线程可以决定是否允许被取消以及如何取消
1 | |
pthread_attr_t定义了一套完整的线程属性
1 | |
线程库定义了一系列函数来操作它。
1 | |
detachstate有两个值,PTHREAD_CREATE_JOINABLE(默认值)和PTHREAD_CREATE_DETACH(脱离线程)。脱离线程在退出时将自行释放其占用的系统资源。可以使用pthread_detach来将线程设为脱离线程。
stack相关的属性是线程堆栈,一般来说不需要自己管理,因为Linux默认为每个线程分配了足够的堆栈空间(一般是8MB)。可以使用ulimt -s来查看或修改该默认值。
guardsize是保护区大小,如果guardsize大于0,则系统创建线程的时候会在其堆栈的尾部额外分配guardsize字节的空间,作为保护堆栈不被错误地覆盖的区域。如果使用者通过pthread_attr_setstackaddr或pthread_attr_setstack函数手动设置线程的堆栈,则guardsize属性将被忽略。
schedparam是线程调度参数,它的结构体目前只有一个整型成员sched_priority。
schedpolicy是线程调度策略,有SCHED_FIFO、SCHED_RR、SCHED_OTHER(默认值)。前两种只能用于以超级用户身份运行的进程。
inheritsched,是否继承调用线程的调度属性,有PTHREAD_INHERIT_SCHED和PTHREAD_EXPLICIT_SCHED两个值。前者表示继承,这种情况下再设置新的调度参数属性将没有任何效果,后者表示调用者要明确地指定新线程的调度参数。
scope,线程间竞争CPU的范围,即线程优先级的有效范围。POSIX定义了PTHREAD_SCOPE_SYSTEM和PTHREAD_SCOPE_PROCESS两个可选值,前者表示所有线程一起竞争,后者表示仅与属于同一进程的线程竞争CPU。目前Linux只支持PTHREAD_SCOPE_SYSTEM。
POSIX信号量
常用的POSIX信号量
1 | |
互斥锁
1 | |
还可以使用下面的方式初始化
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
获取和设置互斥锁属性的函数有
1 | |
属性pshared指定是否允许跨进程共享互斥锁,PTHREAD_PROCESS_SHARED和PTHREAD_PROCESS_PRIVATE
属性type指定互斥锁类型
- PTHREAD_MUTEX_NORMAL,普通锁,是默认类型,当一个线程对一个普通锁加锁以后,其余请求该锁的线程将形成一个等待队列,并在该锁解锁后按优先级获得它。这种锁类型保证了资源分配的公平性。但这种锁也容易引发问题:一个线程如果对一个已经加锁的普通锁再次加锁,将引发死锁;对一个已经被其他线程加锁的普通锁解锁,或者对一个已经解锁的普通锁再次解锁,将导致不可预期的后果。
- PTHREAD_MUTEX_ERRORCHECK,检错锁。一个线程如果对一个已经加锁的检错锁再次加锁,则加锁操作返回EDEADLK。对一个已经被其他线程加锁的检错锁解锁,或者对一个已经解锁的检错锁再次解锁,则解锁操作返回EPERM。
- PTHREAD_MUTEX_RECURSIVE,嵌套锁。这种锁允许一个线程在释放锁之前多次对它加锁而不发生死锁。不过其他线程如果要获得这个锁,则当前锁的拥有者必须执行相应次数的解锁操作。对一个已经被其他线程加锁的嵌套锁解锁,或者对一个已经解锁的嵌套锁再次解锁,则解锁操作返回EPERM。
- PTHREAD_MUTEX_DEFAULT,默认锁。一个线程如果对一个已经加锁的默认锁再次加锁,或者对一个已经被其他线程加锁的默认锁解锁,或者对一个已经解锁的默认锁再次解锁,将导致不可预期的后果。这种锁在实现的时候可能被映射为上面三种锁之一。
条件变量
条件变量用于在线程之间同步共享数据的值。条件变量提供了一种线程间的通知机制:当某个共享数据达到某个值的时候,唤醒等待这个共享数据的线程。
1 | |
同样可以通过pthread_cond_t cond = PTHREAD_COND_INITIALIZER;初始化。
有时候我们可能想唤醒一个指定的线程,但pthread没有对该需求提供解决方法。不过我们可以间接地实现该需求:定义一个能够唯一表示目标线程的全局变量,在唤醒等待条件变量的线程前先设置该变量为目标线程,然后采用广播方式唤醒所有等待条件变量的线程,这些线程被唤醒后都检查该变量以判断被唤醒的是否是自己,如果是就开始执行后续代码,如果不是则返回继续等待。
线程同步机制包装类
可以将这些同步机制分别封装成类方便复用代码,符合RAII。
多线程环境
线程和进程
子进程并不会复制父进程的所有进程,而是复制调用fork的那个线程,并且自动继承父进程中互斥锁、条件变量的状态。这引起了一个问题,子进程可能不清楚从父进程继承而来的互斥锁的具体状态,这个互斥锁可能被加锁了,但并不是由调用fork函数的那个线程锁住的,而是由其他线程锁住的。pthread提供了一个专门的函数pthread_atfork以确保fork调用后父进程和子进程都拥有一个清楚的锁状态。
1 | |
prepare句柄将在fork调用创建出子进程之前被执行,它可以用来锁住所有父进程中的互斥锁。parent句柄则是fork调用创建出子进程之后,而fork返回之前,在父进程中被执行。它的作用是释放所有在prepare句柄中被锁住的互斥锁。child句柄是fork返回之前,在子进程中被执行,也是用于释放所有在prepare句柄中被锁住的互斥锁。
当其他线程加锁时,prepare试图acquire会被阻塞,直到其他线程释放锁,此时prepare能正常获得锁,然后在parent和child中分别释放,就能使得其他线程锁的状态都能释放。
线程和信号
在多线程环境下,设置进程信号掩码时不应用sigprocmask,而应使用下面的
1 | |
进程中的所有线程共享该进程的信号,线程库将根据线程掩码决定把信号发送给哪个具体的线程。所有线程共享信号处理函数,当我们在某个线程中设置了某个信号的信号处理函数后,它将覆盖其他线程为同一个信号设置的信号处理函数。因此,一般情况下应定义一个专门的线程来处理所有的信号避免意外出错。这可以通过如下两个步骤来实现:
- 在主线程创建出其他子线程之前就调用pthread_sigmask来设置好信号掩码,这样所有新创建的子线程都将自动继承这个信号掩码,所有线程都不会响应被屏蔽的信号
- 在专门的线程处理函数中调用如下函数
1 | |
可以使用下面的函数将信号发送给指定的线程。
1 | |
进程池和线程池
池的子进程的数目一般在3~10个之间,子线程的数目应该和CPU数量差不多。
在服务器启动之初就创建好可以使得子进程没有复制一些不必要的空间,占用资源较少。
服务器调制、调试和测试
最大文件描述符数
ulimit -n查看用户级文件描述符数限制
ulimit -SHn <max-file-number>临时修改
永久修改需要在/etc/security/limits.conf中(分别修改硬限制和软限制)
hard nofile
soft nofile
如果要修改系统级文件描述符限制,可使用sysctl -w fs.file-max=<max-file-number>(临时)
永久修改需在/etc/sysctl.conf中
fs.file-max=
然后执行sysctl -p
调整内核参数
几乎所有的内核模块,包括内核核心模块和驱动程序,都在/proc/sys文件系统下提供了某些配置文件以供用户调整模块的属性和行为,通常一个配置文件对应一个内核参数,文件名就是参数的名字,文件的内容是参数的值,我们可以通过命令sysctl -a查看所有这些内核参数。可以通过直接修改/proc/sys目录下的文件的方式来修改这些系统参数外,也可以使用sysctl
命令来修改它们。这两种修改方式都是临时的。
要永久修改应在/etc/sysctl.conf 文件中加入相应参数及其数值,并执行sysctl -p使之生效。
文件相关
/proc/sys/fs目录下的内核参数都与文件系统相关。
/proc/sys/fs/fs/file-max,系统级文件描述符数限制,修改这个参数是临时修改。一般修改/proc/sys/fs/file-max 后,应用程序需要把/proc/sys/fs/inode-max 设置为/proc/sys/fs/fs/file-max 值的3-4倍,否则可能导致i 节点数不够用。
/proc/sys/fs/epoll/max_user_watches,一个用户能够往epoll 内核事件表注册的事件总量。 它是指该用户打开的所有epoll实例总共能监听的事件数目,而不是单个epoll实例能监听的事件数目。往epoll内核事件表中注册一个事件,在32位系统上大概消耗90字节的内核空间,在64位系统上则消耗160字节的内核空间。所以,这个内核参数限制了epoll使用的内核内存总量。
网络相关
内核中网络模块的相关参数都位于/proc/sys/net 目录下,其中和TCP/IP 协议相关的参数主要位于如下三个目录中:core 、ipv4 、ipv6 。
/proc/sys/net/core/somaxconn,指定listen监听队列里,能够建立完整连接从而进入ESTABLISHED 状态的socket 的最大数目。
/proc/sys/net/ipv4/tcp_max_syn_backlog,指定listen监听队列里,能够转移至ESTABLISHED或者SYN_RCVD状态的socket的最大数目。
/proc/sys/net/ipv4/tcp_wmem,它包含了3个值,分别指定一个socket的TCP写缓存区的最小值、默认值和最大值。
/proc/sys/net/ipv4/tcp_rmem,它包含了3个值,分别指定一个socket的TCP读缓存区的最小值、默认值和最大值。
/proc/sys/net/ipv4/tcp_syncookies,指定是否打开TCP同步标签。同步标签通过启动cookie 来防止一个监听socket因不停的重复接收来自同一个地址的连接请求(同步报文段),而导致listen监听队列溢出(所谓的SYN 风暴)。
gdb调试
调试多进程
单独调试子进程
运行gdb,在gdb里执行attach <pid>
follow-fork-mode
在gdb里set follow-fork-mode <mode>,mode为parent或child,选择程序在执行fork后调试父进程还是子进程。
调试多线程
info threads显示当前所有可调试的线程,gdb会为每一个线程分配一个ID,根据ID来操作对应的线程,ID前有“*”的是当前被调试的线程。
thread <ID>调试目标进程
在调试多线程程序时,默认除了被调试的线程在执行外,其他线程也在继续执行。可以通过set scheduler-locking [off|on|step]设置其他线程的运行状态。off表示不锁定任何线程,这是默认值,on表示只有当前被调试的线程会继续执行,step表示在单步执行的时候只有当前线程会执行。
压力测试
如果是本机测试,可以单纯用I/O复用,因为多线程和多进程本身的调度也要消耗大量时间。
系统检测工具
tcpdump
网络抓包
1 | |
还支持用表达式进一步过滤数据包,操作数分三种,type(类型,包括host、net、port和portrange),dir(方向),proto(协议)
tcpdump net 1.2.3.0/24
tcpdump dst port 13579
tcpdump icmp
tcpdump ip host ernest-laptop and not Kongming20
可以用括号改变优先级,但括号存在时应把tcpdump后面的整个表达式用单引号引起来,或用反斜杠对括号进行转义。
tcpdump 'src 10.0.2.4 and (dst port 3389 or 22)'
此外还允许直接使用数据包中的部分协议字段的内容来过滤数据包,比如仅抓取TCP同步报文段
tcpdump 'tcp[13] & 2 != 0'(TCP头部第14个字节的第2个位是同步标志)
tcpdump 'tcp[tcpflags] & tcp-syn != 0'
lsof
列出当前系统打开的文件描述符
nc
主要被用来快速构建网络连接,以调试客户端、服务器程序。
strace
测试服务器性能的重要工具,跟踪程序运行过程中执行的系统调用和接收到的信号,并将系统调用名、参数、返回值及信号名输出到标准输出或指定文件。
netstat
功能强大的网络信息统计工具,可以打印本地网卡接口上的全部连接、路由表信息、网卡接口信息。不过获取路由表信息和网卡接口信息更实用的是route和ipconfig。
vmstat
是virtual memory statistics的缩写,能实时输出系统的各种资源的使用情况,比如进程信息、内存使用、CPU使用率以及I/O使用情况
可以使用iostat获得磁盘使用情况的更多信息,也可以使用mpstat获得CPU使用的更多信息。vmstat主要用于查看系统内存的使用情况。
ifstat
是interface statistics的缩写,是一个简单的网络流量监测工具。使用ifstat命令可以大概估计各个时段服务器的总输入、输出流量。
mpstat
是multi-processor statistics的缩写,能实时监测多处理器系统上每个CPU的使用情况。mpstat和iostat命令通常都集成在sysstat中。