Effective Modern C++ 笔记
阅读《Effective Modern C++》时记录下的笔记
Type Deduction
Template Deduction
1 | |
Case 1: ParamType is a reference or pointer, but not a universal reference
if expr's type is a reference, ignore the reference part
Then pattern-match expr's type against ParamType to determine T.

非常符合常识
Case 2: ParamType is a universal reference
- If expr is an lvalue, both T and ParamType are deduced to be lvalue
- If expr is an rvalue, the same as case 1.

Case 3: ParamType is neither a pointer nor a reference
- if expr's type is a reference, ignore the reference part.
- If after ignoring expr's reference-ness, expr is const, ignore that, too. If it's volatile, also ignore that.

A more complecated case:

*右边的const表示指针指向的地址不变,即指针的const-ness,在值传递是是可以被丢弃的,而*左边的const表示指针指向的地址的内容不变,这个const-ness需要被保留
For Array && pointer, if by-value, array will be deduced to pointer, if reference, array will still be array, which means the length information is preserved.

用这个特点还可以实现模板函数得到数组长度。
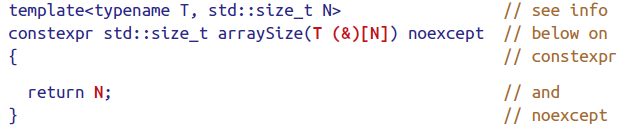
constexpr是为了让其编译时即可用,例如

建议更多使用std::array而不是built in的array
Function

总结

Auto Deduction
基本与template
deduction一致,但对于用{}进行初始化的变量会推导成std::initializer_list<T>类型,T是{}内的值的类型,值必须是单一类型。Template
deduction的T无法直接推导为std::initializer_list.
auto x = {1};
auto x {1};
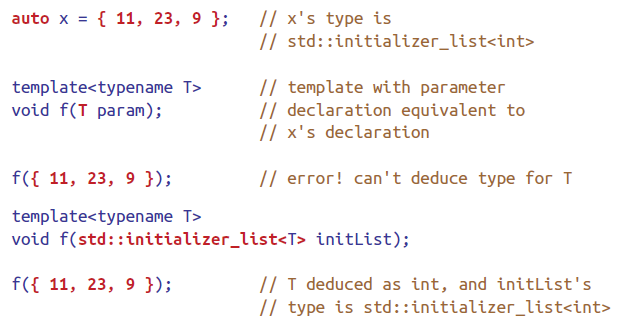
c++14中要确保函数返回值能够推导。此处的auto采用template deduction的规则而不是auto,即不能将{}推导为std::initializer_list.The same is true when auto is used in a parameter type specification in a C++14 lambda.

总结

decltype
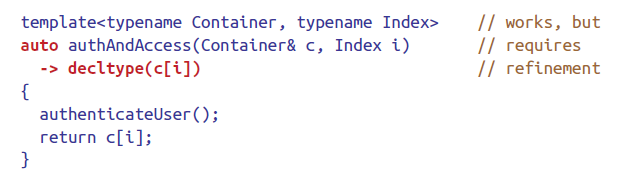
auto在这里并不是类型推导,而是表明采用C++11的trailing return type syntax.这种语法的好处是返回值可以用参数列表里的内容进行推导。
C++11允许单语句的lambda表达式返回类型的推导,C++14则允许所有lambda表达式和函数的推导,也就是说在C++14中上图的-> decltype(c[i])可以被省略。
但是这样做实际上是存在问题的,因为auto的类型推导会消除reference-ness。
C++14引入了语法decltype(auto),表示在类型推导时用decltype的规则。

同样可以用于变量类型的推导。

但是上面的函数无法正确处理右值。下面是最终版本。


decltype对与name和expression有不同的表现。对于name,它产生的就是name声明的类型。对于lvalue表达式,它产生的是lvalue reference。
对于int x, decltype(x)为int,但decltype((x))为int&
注意f2返回了一个局部变量的引用,这是undefined behavior,应当避免!


View deduced type
编译期
利用编译器报错。

运行期
打印typeid(x).name()
typeid(x)会产生std::type_info的object,不同编译器的name方法实现不同,GNU和Clang的编译器的信息不是很易读(i表示int,P表示指针,K表示const),可以用c++filt进行解码,Microsoft的易读。
但是std::type_info::name返回的类型名is treated as if it had been passed to a template function as a by-value parameter.也就是说,它的reference-ness会被忽略,const(以及volatile)会被忽略。所以并不可靠。
用库Boost.TypeIndex(非标准库),该库在不同编译器下都能得到正确的类型

cvr: const、volatile、reference
Auto
涉及到vector的size时建议用auto,因为size的返回类型为std::vector::size_type,太长,而直接用unsigned有时候会出问题。
map的遍历也建议用auto,因为用std::pair<Key, Value>得到它内部的元素时需要注意Key类型往往和map不一致,需要加上const,忽略const会导致奇怪的错误。
在访问std::vector<bool>的元素时不要使用auto。std::vector<T>的操作符[]在T非bool的时候都返回T&,但bool则返回std::vector<bool>::reference,这是因为std::vector<bool>实现时一个bit一个bool变量的值。
std::vector<bool>::reference是一种proxy
class的技术,为更高效的计算等服务,需要支持隐式转换(bool)
一些显式的proxy
class有std::shared_ptr、std::unique_ptr。
Invisible proxy class(e.g.
std::vector<bool>::reference)不适合用auto。更准确地说,在使用auto时,需要先将Invisible
proxy class进行类型转换(explicitly typed initializer idiom, e.g.
static_cast)

Modern C++
Initialize with () and
{} can be used in the widest variety of contexts, prevent implicit narrowing conversions, and immune to C++'s most vexing parse(i.e. constructor with 0 arguments).
但需要注意auto和{}的冲突。


对于含std::initializer_list的constructor,{}会优先该constructor(会尝试类型转换,隐式(包括narrow conversion)、显式)。

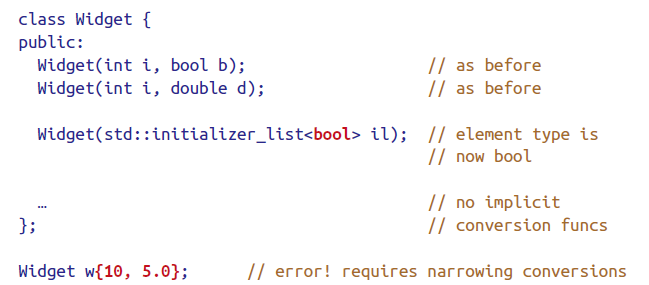

空的{}会调用default constructor而不是Std::initializer_list constructor

模板编写存在的问题

到底应该采用上面这种还是下面这种只有调用者知道。这个问题留待std::make_unique、std::make_shared解决。

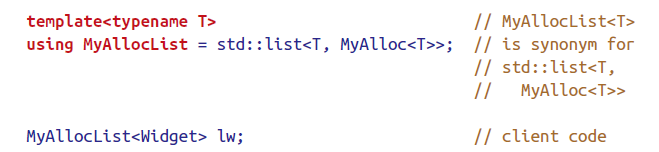
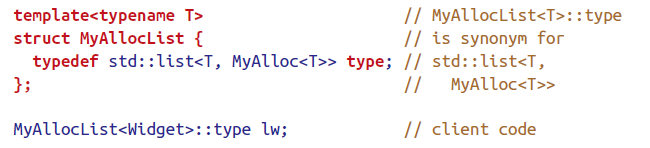
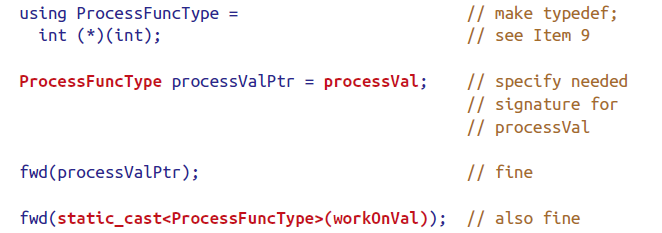
Use alias declaration instead of typedef
alias declaration在模板方面更具优势。


Use scoped enums instead of unscoped enums

enum class的优势:
- scoped,不会污染命名空间
- 不会隐式转换为整型(想要转换则用cast)
scoped enum和unscoped enum都可以前向声明,默认underlying type为int,可以用:指定underlying type.
enum的definition也可以指定underlying type。
unscoped enum在访问(std::get<>)std::tuple的时候较为方便使用。

即使用模板函数结合scoped enum,

最终仍需要这样。

依然较为麻烦。

Prefer deleted functions to private undefined ones
private undefined ones may still be used within the class and its friend class, and will fail when link. But use delete, it will fail when compile.
deleted function通常声明为public,这是因为编译器优先检测accessibility再检测deleted,如果声明为private,那么编译器报错会是访问权限不够而不是deleted。
delete也可以用于防止隐式转换。

float也被reject是因为C++倾向于将float转double。
delete还可以用于删除特化的模板函数。(private无法做到这点因为模板特化必须在namespace scope而不是class scope)

Declare overriding functions override
函数签名可以包括the function's reference qualifier,&表明当*this为lvalue时,&&表明当*this为rvalue时
override的条件

Because little difference of function signatures between base class and derived class may cause you not actually overriding a function, it's necessary to use override keywords to explicitly tell the compiler you want to override the base function so that when some difference exists, compiler can send wrong messages correctly.
override虽然是关键字,但它只在特定位置被识别为关键字,也就是说函数名可以是override。

Prefer const_iterators to iterators
C++98使用const_iterator相当不方便,C++11和C++14则很好地支持了这一点。
C++11的container仅支持non-member function的begin、end,但并不支持non-member function的cbegin、cend。可以实现下图的cbegin、cend。

std::begin在container为const时返回的类型为const_iterator。

Declare functions noexcept if they won't emit exceptions
C++98用throw()声明函数可能抛出的所有异常,一旦实现修改,可能对整体代码有较大影响。且执行时需要检查抛出异常是否在throw声明的函数中,一旦不在,需要抛出异常、终止程序,这对性能有一定开销。
C++11只在意是否会抛出异常,即noexcept关键词。声明noexcept可以在编译时做更多的优化。
C++11中memory deallocation functions(delete and delete[])和destructor默认noexcept,除非显式声明(比如noexcept(false))
条件noexcept

当声明一个函数noexcept时,compiler并不会检查它的具体实现是否调用了non-noexcept的函数,因为一些历史遗留的函数可能是noexcept但并没有这样声明。

Use constexpr whenever possible
const的object未必在编译时已知,而constexpr的object一定已知。
即all constexpr objects are const, but not all const objects are constexpr
C++11 constexpr只能一个语句,也就是return语句。可以用?:实现if-else,用递归实现循环。
C++14则没有该要求。
constexpr function只能用和返回literal type(除void外的内置类型以及constexpr的构造函数的用户自定义类)
C++11中constexpr的member function是隐式const的,所以不能修改成员变量(constructor除外),且void不是literal type,所以setters不能设为constexpr,但C++14移除了这两个限制,所以可以。
constexpr在传入编译时已知的参数时是编译器已知的,否则是运行时已知的。

Make const member functions thread safe
使用mutable关键字的成员变量使得即使是const的member function也可以对其进行修改。
一般情况下,const的member function是线程安全的,但由于mutable的成员变量可以被const的member function修改,该函数不再线程安全。
如果只是添加一个互斥锁,

看样子能解决问题,但实际上由于std::mutex只能move,不能copy,反而使得Polynomial无法被copy了。
但没有更好的解决办法。
当只需要维护一个变量时,std::atomic可能是更高效的选择。

Understand special member function generation
Generated special member functions are implicitly public and inline, and they are non-virtual unless it is a destructor derived from a virtual destructor.
只有用到了copy、move,响应的special member function才会被生成。
copy constructor和copy assignment operator之间相互独立
default move constructor、move assignment will try to do memberwise move. If move operation is disabled for one member, use copy instead for that member.
两个copy operation之间相互独立,声明了一个并不会阻止编译器自动生成另一个。
两个move operation之间不独立, 声明一个会阻止编译器自动生成另一个。
如果至少显式声明了一个copy operation,编译器将不会生成move operations。
反过来,如果至少显式声明了一个move operation,编译器也不会生成copy operations.

It is better to obey the rule for copy too.
如果编译器生成的special memory function能满足需求,那么可以显式地用=default。
即使编译器生成的special memory function满足你的需求,也建议用=default显式声明,因为简单的修改可能对该未声明的函数产生难以察觉的影响(比如加入destructor导致默认的move operations失效,最终调用了copy,导致效率降低)

模板函数不会影响special memory function的产生。


Smart Pointers
除非你要用C++98,否则应用std::unique_ptr而不是std::auto_ptr
Use std::unique_ptr for exclusive-ownership resource management
可以将std::unique_ptr的性能开销看作与raw ptr相同。(用默认的deleter或stateless function object时)
move-only
unique_ptr的第二个模板参数可以指定析构函数
用函数需要函数指针,但用stateless function object(比如lambda expressions with no captures)则unique_ptr不需要额外空间。
std::unique_ptr有两种形式,std::unique_ptr<T>和std::unique_ptr<T[]>,所以不存在模糊性。
std::unique_ptr<T>没有[]操作符,std::unique_ptr<T[]>没有*和->操作符
std::unique_ptr可以轻松地转换成std::shared_ptr
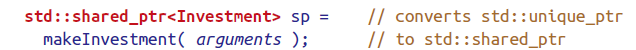

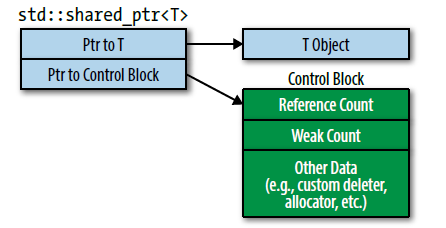
Use std::shared_ptr for shared-ownership resource management
std::shared_ptr占用的空间是原生指针的两倍,因为它还需要一个指向reference count的指针。
reference count的内存必须动态分配(std::make_shared可以避免动态分配),这样多个std::shared_ptr才能指向同一个。
Increment and decrement on reference count must be atomic.
Move不需要改变reference count,因而快于copy。
std::shared_ptr同样支持自定义deleter,但略有不同,不需要模板的第二个参数。这使得不同deleter属于同一类型,更灵活。
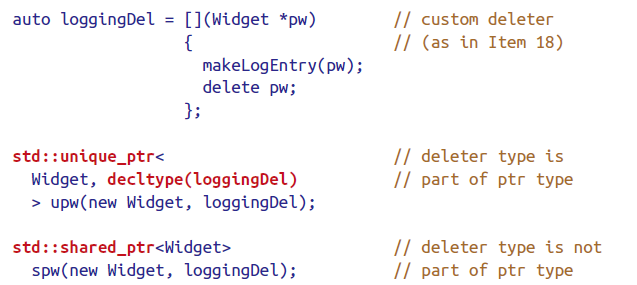
自定义deleter的大小并不会影响std::shared_ptr的大小。

使用shared_ptr容易犯以下错误:
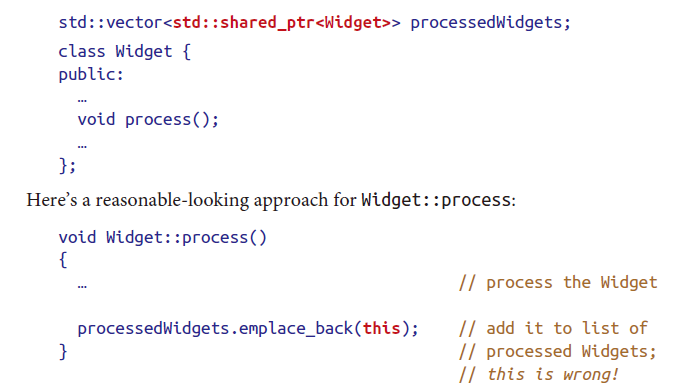
emplace_back(this)会重复申请control block。
一种可行的解决方法是将该类T继承自std::enable_shared_from_this<T>
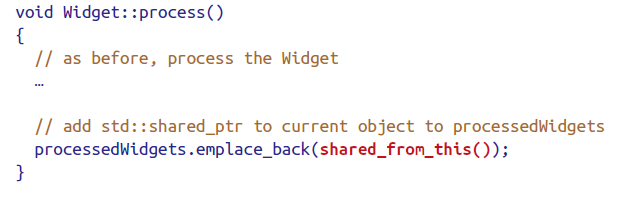
使用shared_from_this时必须确保该object已有shared_ptr。
为实现这点,该类往往将ctor声明为private,用工厂函数创建。

control block甚至还有一个虚函数,用于确保指向的物体被正确析构。
std::shared_ptr不能用于数组,也不应用于数组。

Use std::weak_ptr for std::shared_ptr-like pointers that can dangle
std::weak_ptr没有dereference操作。
std::weak_ptr::expired()用于检测指针是否悬空,但实际使用中往往容易线程不安全。
std::weak_ptr::lock()用于检测指针是否悬空,不悬空则返回shared_ptr,这就使得之后的使用中不会悬空。
当不需要参与对象生命周期的管理,而只在意指针是否悬空时,采用。
可以避免shared_ptr之间的循环引用的问题。
std::weak_ptr的开销可以看作和shared_ptr一致。

Prefer std::make_unique and std::make_shared to direct use of new
std::make_unique在C++14才有,在C++11中可以这样定义。

std::allocate_shared和std::make_shared类似,但它的第一个参数指定了一个allocator对象用于内存分配。
用new的指针作为参数初始化智能指针可能会由于异常发生内存泄漏。

如果先执行new Widget,再执行computePriority(),再构造std::shared_ptr,在执行computePriority的时候抛出异常,那么new Widget分配的内存空间将被泄漏。而使用std::make_shared则不会有该问题(exception safety)。
用new出来的指针作为参数初始化shared_ptr需要两次内存分配(一次new,一次control block),但std::make_shared会一次性分配内存给这两个内容,因而效率更高。
make的缺点
- 不能指定deleter
- 采用parentheses initializer而不是braced initializer。如果想要使用braced initializer,可以用auto声明{}对象再传入。
- 由于control block和object的内存空间是一并allocate的,所以必须一起deallocate。所以只有当所有std::shared_ptr和std::weak_ptr被释放之后(reference count和weak count都为0),它们的空间才会被释放(这也是为什么需要weak count)。所以对于一些特别大的而且最后一个指针被析构特别迟的object,make并不是很实用,直接new对内存的利用效率会更高(只需要等最后一个shared_ptr被析构就会被释放)。
- 对于自己定义了new和delete的类,make并不适用,因为它们往往只分配自己需要的确切空间。
事实上,只要注意一点,new也可以exception safety.
但是注意这次传递的是lvalue,也就意味着copy,而copy对于std::shared_ptr意味着atomic的increment,并不高效,应采用下面的方法。

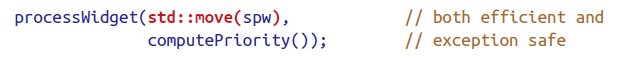

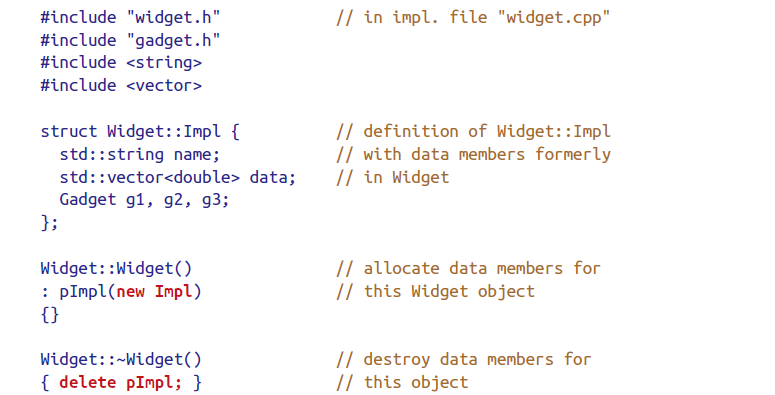
When using the Pimpl Idiom, define special member functions in the implementation file
Pimpl Idiom in C++98

在上面的实现中,widget.h需要include
<string>、<vector>、gadget.h,这意味着编译更加费时而且一旦这些文件有修改都需要重新编译。
而Pimpl
Idiom将这一系列private且没有getter的成员变量封装到struct中,struct的具体成员组成放到.cpp中,使得include
widget.h的文件不再include
<string>、<vector>、gadget.h。

Pimpl Idiom with smart pointer

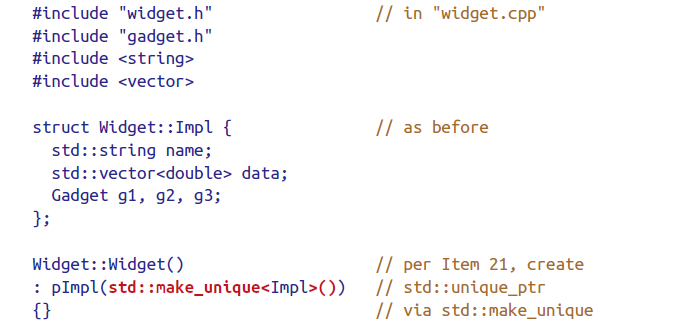
这样子的实现看样子没有问题且能正确编译,但是一旦使用该类编译器就会报错。这是因为默认的析构函数是inline的,在头文件中,而头文件的该类型是incomplete的,所以应在头文件中声明该析构函数并在.cpp中实现(=default或={}),确保实现时类型已经complete。(此问题只对std::unique_ptr出现,std::shared_ptr不要求类型完整)
值得注意的是,由于声明了析构函数,编译器将不会产生move operations,而move对于std::shared_ptr的效率来说意义较大,所以也应声明并在cpp中实现(如果在.h中实现会报相同的错,因为move需要destroy)
此外,由于编译器不会为含move-only的成员变量的类生成copy oprations,需要自己实现deep copy。

Rvalue References, Move Semantics and Perfect Forwarding
std::move and std::forward
它们实际上不做任何事(runtime),而只是cast。
std::move无条件地将它的参数cast成rvalue
std::forward cast to rvalue only if its argument was initialized with an rvalue.(也就是是让lvalue保持lvalue,rvalue保持rvalue。由于函数的参数始终为lvalue,所以这是必要的)
don't declare objects const if you want to be able to move from them. 这样的做法经常会变成copy。

Distinguish universal references from rvalue references
universal reference
共两种情况
作为模板参数,必须严格是
T&&(const T&&、std::vector<T>&&之类的都不是universal reference)且存在类型推导
auto
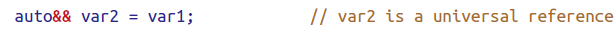
下面的例子由于不存在类型推导所以不是universal reference.
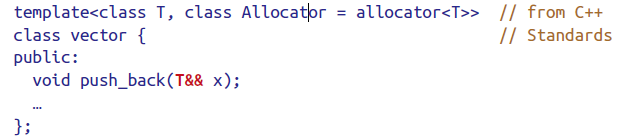
下图则属于univeresal reference。
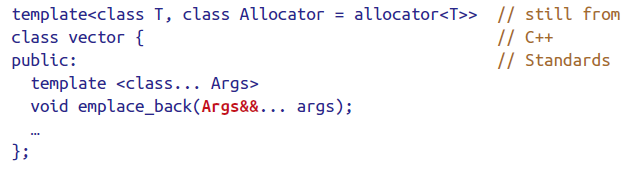
auto&&通常出现在C++14的lambda表达式的参数列表中。

Use std::move on rvalue references, std::forward on universal references
即使一个物体不支持move,在作为函数的返回值时也可以将它转成rvalue,这并不会影响什么,程序会照常copy它,而当它后来改变成支持move时就能自然而然得到效率提高。
没有必要将函数内部使用且返回的局部变量cast成rvalue,因为C++一直有一个机制return value optimization(RVO),即当函数的返回值是它内部的局部变量时,将要返回的局部变量直接构造在分配好的用于返回的内存空间,这样就避免了copy。
而一旦使用std::move,就会不满足RVO的条件,那么函数存放返回值的地方就不会存着该局部变量,需要真正执行一次move。
当函数有不同的执行路径,可能返回不同的局部变量时,RVO可能不会被实现。但这种情况依然不需要使用std::move。因为当编译器知道自己不能实现时,会自行将返回值转成右值,即std::move。
perfect-forward不会为了确认参数类型而构造临时object(比如literal的字符串传给universal reference,再forward,这个literal在传给universal reference的时候不需要被构造,而是直接forward(literal))

Avoid overloading on universal references
universal reference能匹配绝大多数的参数,如果重载了int,但调用时用short,short会被universal reference匹配上而不是int,这往往会造成不想要的结果。
Compiler产生的copy是const T&,一旦传参数时传的不是const,universal reference的函数就会因为准确匹配而代替copy操作。
当涉及到继承时,copy和move也不会像想象中那样运作。
Person实现了universal reference

Person(rhs)和Person(std::move(rhs))都会匹配上universal reference(rhs是SpecialPerson而不是Person,这就导致没法直接匹配上)。

Familiarize yourself with alternatives to overloading on universal references
Use tag dispatch
通过引入一个新的参数来解决问题,只要该参数在我们想调用重载函数时不会和universal reference的参数匹配上就可以了。
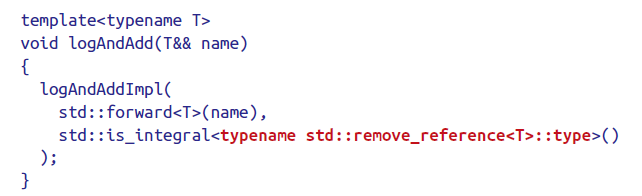
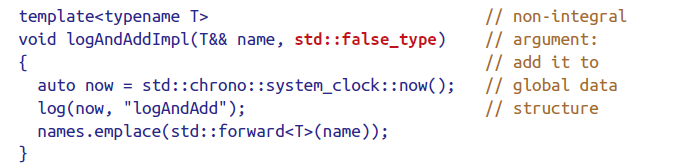

一些编译器会优化掉这些运行时并不起作用的tag。
但这还只解决了部分问题,仍存在两个问题。
编译器生成的copy是const T&,想调用copy时依然可能被universal reference抢占。
子类调用它的copy、move依然会出现匹配上universal reference的问题。
第一个问题可以用以下方法解决。(std::decay用于去reference-ness和const-ness和volatile-ness)

第二个问题的解决需要用到std::is_base_of<T1, T2>,当T1是T2基类时为true。


再将int问题一并解决,最终解决方案如下

Trade-off
perfect-forward不会为了确认参数类型而构造临时object(比如literal的字符串传给universal reference,再forward,这个literal在传给universal reference的时候不需要被构造,而是直接forward(literal))。
一些参数无法被forward。
编译器的报错可能难以读懂。可以用static_assert辅助。

但是由于std::forward在static_assert的上方,static_assert的信息往往在很长的std::forward报错的下方。

Understand reference collapsing
模板实例化的时候会发生reference collapsing,将reference-to-reference变成reference.
If either reference is an lvalue reference, the result is an lvalue reference. Otherwise (i.e., if both are rvalue references) the result is an rvalue reference.
由于该机制,forward可以如下图简单实现。

auto同样会发生reference collapsing。
所以universal reference的本质就是type deduction区分lvalue和rvalue、reference collapsing发生。

Assume that move operations are not present, not cheap and not used
move operations并不总像我们想象中那样快。
对于大多数标准容器,它们内部有指针,指向heap上分配的空间,这部分的move是很快的,只需要指针的赋值。
但对于特殊的容器,比如std::array,它的数据是放在object内部的,所以move时需要将整个object内的数据move,并不很快。
std::string的很多种实现里都有一种small string optimization(SSO)的机制,即将长度小于等于15的字符串直接放在object内部而不是动态分配heap。而短字符串是很多应用场景下的字符串用法,所以它的move也并没有想象中那么快。
由于C++98的代码遗留问题,为了保证exception safety,标准库中的一些move只有当noexcept的时候才会被编译器使用

Familiarize yourself with perfect forwarding failure cases
对于这样一个函数

如果下面两种形式都能正确被编译执行,那就是成功forward。

- braced initializers
- compiler不会直接将{}类型推导为std::initializer_list
- 可以引入一个auto变量(std::initializer_list)
- declaration-only integral const static data members
- 这种变量实际上不会被分配内存,是编译期的常量,所以没法生成reference。
- 可以通过definition解决。
- template and overloaded function names
- 对于有重载或模板类的函数,无法正确推导出具体是哪个。
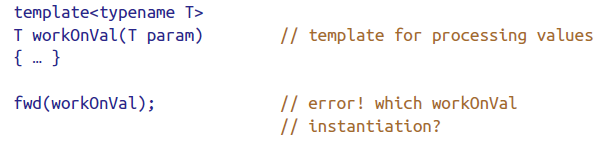
- bitfields
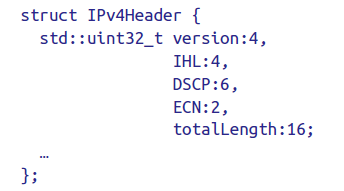
- bitfield实现了按位的任意拆分访问,因为无法生成对任意位的reference,所以是不允许对非const的bitfield进行的。
- 通过copy解决


Lambda Expressions
lambda表达式会被编译成closure class,运行时会生成closure。
Avoid default capture modes
当使用default by-reference [&] capture时,往往容易忽略捕捉到的变量的生命周期,导致dangling。比如将lambda表达式存入vector中,而该lambda中含有局部变量的reference,一旦离开这个scope就会导致lambda里面捕捉的reference dangling。
静态变量是不需要捕获也不能显式捕获的,静态变量相当于引用,可以直接在lambda表达式中使用。当使用default by-value [=] capture时,容易误以为是值捕获。
当想要捕获成员变量(divisor)时

它的实际效果其实如下图
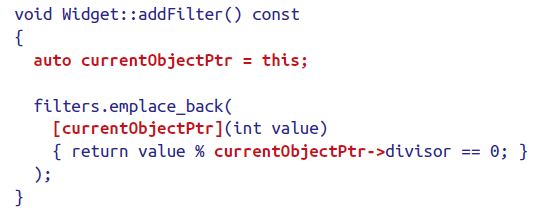
并不是我们想要的值捕获

Use init capture to move objects into closures
C++14引入了init capture(generalized lambda capture)机制,类似于函数的初始化,等号左边的作用域和右边的作用域不同。

C++11可以用std::bind模拟。

std::bind会将左值以copy的方式,右值以move的方式传递。
声明为const是因为默认情况下lambda表达式的函数为const。

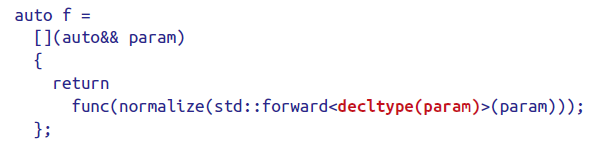
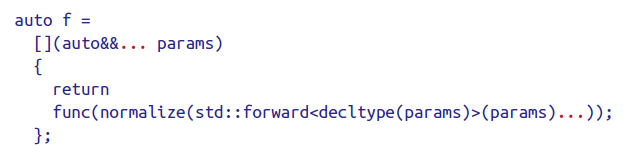
Use delctype on auto&& parameters to std::forward them
C++14有一个新特性——generic lambdas,即参数列表中的参数类型可以用auto。

Prefer lambdas to std::bind
如果使用std::bind,对于有重载的函数,由于编译器不能推断是哪个,会编译错误。为解决该错误需要static_cast函数的类型。
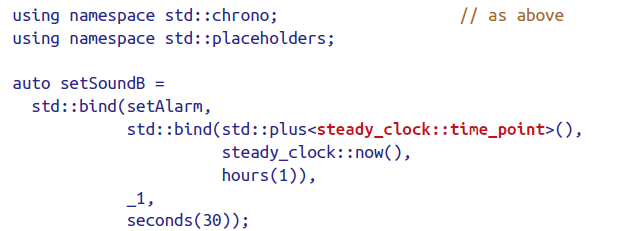
使用std::bind对某些表达式需要较复杂的处理。

上面的lambda表达式不能直接改成下面的。

而应该这样。

不过C++11由于模板参数不能省略,则更麻烦一点。
由于用std::bind实现可能更复杂,这也导致它更难以被inline实现。
还有例子可以体现复杂性。


构造std::bind时std::bind始终复制它的参数,而调用构造好的bind object时传递的参数为reference。
在C++14中,没有理由继续使用std::bind。
但在C++11中,由于lambda表达式不支持auto,可以用std::bind调用模板函数来实现;由于lambda表达式不支持move capture,可以用std::bind结合lambda表达式实现。

The Concurrency API
Prefer task-based programming to thread-based
std::async是task-based的,它可以减轻管理线程的负担,而且可以得到执行的任务的返回值。而std::thread则无法得到返回值,并且如果throw了exception,那么将导致程序终止。
除非对线程很了解并且需要自定义线程的管理方式来极大化运行效率、涉及底层API的调用或者需要设置线程的优先级,否则最好使用std::async。

Specify std::launch::async if asnchronicity is essential
std::async可以用std::launch指定policy。std::launch::async使得它只能在其他线程上运行,std::launch::deferred使得它只有在它返回的future的get或wait方法被调用时才会被执行,也就是同步在该线程上执行。std::async的默认值实际上就是std::launch::async|std::launch::deferred。
默认的std::async不能很好地和thread_local variable一同使用,因为无法控制该task在哪个线程中使用。
deferred的线程不会被wait_for阻塞,而且由于它只有在它返回的future的get或wait方法被调用时才会被执行,下面的代码并不能正常工作(当fut为deferred的时候)。

这种问题并不容易被发现,只有当线程使用较多,程序倾向于分配deferred的时候才容易发生。
为了判断fut是否是deferred,可以用wait_for函数,因为如果是deferred则它的返回值是std::future_status::deferred。由于不需要等待,所以wait_for(0s)。

可以直接使用默认的std::async的场合
- fut的get或wait一定会被调用 或者 该任务允许不被执行
- 使用wait_for或wait_until的地方应对deferred作检查
- 不在意用的是那个thread的thread_local变量
当需要异步时,可以直接指定。下面提供了一个方便的函数。
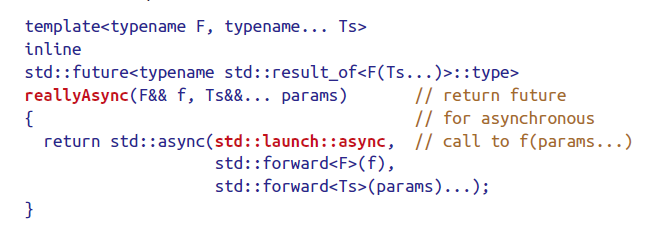
C++14中可以直接用auto指定返回类型。

Make std::threads unjoinable on all paths
std::thread object: C++线程的实例
an underlying thread: 计算机中真正的线程
std::thread object有两个状态,joinable和unjoinable。joinable指underlying thread能够或者正在运行,被阻塞或等待调度。unjoinable包括default-constructed、be moved from、have been joined、have been detached(即没有underlying的thread就是unjoinable)。
joinable的thread的析构发生时,程序会终止。
因而使得所有thread在out of scope的时候都unjoinable是很重要的。

注意std::thread最后声明,因为std::thread一旦被初始化随时可能运行,要确保其他变量已经初始化好了。对于unjoinable的对象调用join、detach是未定义行为,应避免。
由于std::thread object从joinable变成unjoinable只能通过function call比如join、detach、move operation,而在析构发生时它们不会被调用,所以不会存在多线程的data race现象导致析构时的判断过时。
析构时join对性能有一定影响,可能会造成不必要的等待(以及hung program)。析构时detach会造成预料之外的数据修改。
要想更好地实现,需要与underlying thread进行通信。
由于上面的ThreadRAII实现了析构函数,编译器将不会生成move oprations。但理应支持。


Be aware of varying thread handle destructor behavior
线程的返回值既不能存在被调用的线程(callee)中(因为执行完就销毁了),也不能以future的形式存放在调用线程的线程(caller)中(因为future可以用来move创建std::shared_future,std::shared_future又可以被多次copy),而是放在动态申请的空间Shared State中。
- The destructor for the last future referring to a shared state for a non-deferred task launched via std::async blocks until the task completes
- The destructor for all other futures simply destroys the future object.

Something else to learn
The Curiously Recurring Template Pattern(CRTP)
std::multiset
std::enable_if、SFINAE
std::launch::async当真的没有线程可以分配时会发生什么
C++14支持单引号作为数字分隔符
std::promise